复制项目
This commit is contained in:
42
docs/contrib/README.md
Normal file
42
docs/contrib/README.md
Normal file
@@ -0,0 +1,42 @@
|
||||
# Contrib Documentation Index
|
||||
|
||||
## 📚 General Information
|
||||
- [📄 README](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/README.md) - General introduction to the contribution documentation.
|
||||
- [📑 Development Guide](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/development.md) - Guidelines for setting up a development environment.
|
||||
|
||||
## 🛠 Setup and Installation
|
||||
- [🌍 Environment Setup](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/environment.md) - Instructions on setting up the development environment.
|
||||
- [🐳 Docker Installation Guide](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/install-docker.md) - Steps to install Docker for container management.
|
||||
- [🔧 OpenIM Linux System Installation](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/install-openim-linux-system.md) - Guide for installing OpenIM on a Linux system.
|
||||
|
||||
## 💻 Development Practices
|
||||
- [👨💻 Code Conventions](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/code-conventions.md) - Coding standards to follow for consistency.
|
||||
- [📐 Directory Structure](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/directory.md) - Explanation of the repository's directory layout.
|
||||
- [🔀 Git Workflow](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/git-workflow.md) - The workflow for using Git in this project (note the file extension error).
|
||||
- [💾 GitHub Workflow](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/github-workflow.md) - Workflow guidelines for GitHub.
|
||||
|
||||
## 🧪 Testing and Deployment
|
||||
- [⚙️ CI/CD Actions](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/cicd-actions.md) - Continuous integration and deployment configurations.
|
||||
- [🚀 Offline Deployment](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/offline-deployment.md) - How to deploy the application offline.
|
||||
|
||||
## 🔧 Utilities and Tools
|
||||
- [📦 Protoc Tools](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/protoc-tools.md) - Protobuf compiler-related utilities.
|
||||
- [🔨 Utility Go](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/util-go.md) - Go utilities and helper functions.
|
||||
- [🛠 Makefile Utilities](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/util-makefile.md) - Makefile scripts for automation.
|
||||
- [📜 Script Utilities](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/util-scripts.md) - Utility scripts for development.
|
||||
|
||||
## 📋 Standards and Conventions
|
||||
- [🚦 Commit Guidelines](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/commit.md) - Standards for writing commit messages.
|
||||
- [✅ Testing Guide](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/test.md) - Guidelines and conventions for writing tests.
|
||||
- [📈 Versioning](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/version.md) - Version management for the project.
|
||||
|
||||
## 🖼 Additional Resources
|
||||
- [🌐 API Reference](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/api.md) - Detailed API documentation.
|
||||
- [📚 Go Code Standards](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/go-code.md) - Go programming language standards.
|
||||
- [🖼 Image Guidelines](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/images.md) - Guidelines for image assets.
|
||||
|
||||
## 🐛 Troubleshooting
|
||||
- [🔍 Error Code Reference](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/error-code.md) - List of error codes and their meanings.
|
||||
- [🐚 Bash Logging](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/bash-log.md) - Logging standards for bash scripts.
|
||||
- [📈 Logging Conventions](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/logging.md) - Conventions for application logging.
|
||||
- [🛠 Local Actions Guide](https://github.com/openimsdk/open-im-server-deploy/tree/main/docs/contrib/local-actions.md) - How to perform local actions for troubleshooting.
|
||||
5
docs/contrib/api.md
Normal file
5
docs/contrib/api.md
Normal file
@@ -0,0 +1,5 @@
|
||||
## Interface Standards
|
||||
|
||||
Our project, OpenIM, adheres to the [OpenAPI 3.0](https://spec.openapis.org/oas/latest.html) interface standards.
|
||||
|
||||
> Chinese translation: [OpenAPI Specification Chinese Translation](https://fishead.gitbook.io/openapi-specification-zhcn-translation/3.0.0.zhcn)
|
||||
49
docs/contrib/bash-log.md
Normal file
49
docs/contrib/bash-log.md
Normal file
@@ -0,0 +1,49 @@
|
||||
## OpenIM Logging System: Design and Usage
|
||||
|
||||
**PATH:** `scripts/lib/logging.sh`
|
||||
|
||||
|
||||
|
||||
### Introduction
|
||||
|
||||
OpenIM, an intricate project, requires a robust logging mechanism to diagnose issues, maintain system health, and provide insights. A custom-built logging system embedded within OpenIM ensures consistent and structured logs. Let's delve into the design of this logging system and understand its various functions and their usage scenarios.
|
||||
|
||||
### Design Overview
|
||||
|
||||
1. **Initialization**: The system begins by determining the verbosity level through the `OPENIM_VERBOSE` variable. If it's not set, a default value of 5 is assigned. This verbosity level dictates the depth of the log details.
|
||||
2. **Log File Setup**: Logs are stored in the directory specified by `OPENIM_OUTPUT`. If this variable isn't explicitly set, it defaults to the `_output` directory relative to the script location. Each log file is named based on the date to facilitate easy identification.
|
||||
3. **Logging Function**: The `echo_log()` function plays a pivotal role by writing messages to both the console (stdout) and the log file.
|
||||
4. **Logging to a file**: The `echo_log()` function writes to the log file by appending the message to the file. It also adds a timestamp to the message. path: `_output/logs/*`, Enable logging by default. Set to false to disable. If you wish to turn off output to log files set `export ENABLE_LOGGING=flase`.
|
||||
|
||||
### Key Functions & Their Usages
|
||||
|
||||
1. **Error Handling**:
|
||||
- `openim::log::errexit()`: Activated when a command exits with an error. It prints a call tree showing the sequence of functions leading to the error and then calls `openim::log::error_exit()` with relevant information.
|
||||
- `openim::log::install_errexit()`: Sets up the trap for catching errors and ensures that the error handler (`errexit`) gets propagated to various script constructs like functions, expansions, and subshells.
|
||||
2. **Logging Levels**:
|
||||
- `openim::log::error()`: Logs error messages with a timestamp. The log message starts with '!!!' to indicate its severity.
|
||||
- `openim::log::info()`: Provides informational messages. The display of these messages is governed by the verbosity level (`OPENIM_VERBOSE`).
|
||||
- `openim::log::progress()`: Designed for logging progress messages or creating progress bars.
|
||||
- `openim::log::status()`: Logs status messages with a timestamp, prefixing each entry with '+++' for easy identification.
|
||||
- `openim::log::success()`: Highlights successful operations with a bright green prefix. It's ideal for visually signifying operations that completed successfully.
|
||||
3. **Exit and Stack Trace**:
|
||||
- `openim::log::error_exit()`: Logs an error message, dumps the call stack, and exits the script with a specified exit code.
|
||||
- `openim::log::stack()`: Prints out a stack trace, showing the call hierarchy leading to the point where this function was invoked.
|
||||
4. **Usage Information**:
|
||||
- `openim::log::usage() & openim::log::usage_from_stdin()`: Both functions provide a mechanism to display usage instructions. The former accepts arguments directly, while the latter reads them from stdin.
|
||||
5. **Test Function**:
|
||||
- `openim::log::test_log()`: This function is a test suite to verify that all logging functions are operating as expected.
|
||||
|
||||
### Usage Scenario
|
||||
|
||||
Imagine a situation where an OpenIM operation fails, and you need to ascertain the cause. With the logging system in place, you can:
|
||||
|
||||
- Check the log file for the specific day to find error messages with the '!!!' prefix.
|
||||
- View the call tree and stack trace to trace back the sequence of operations leading to the failure.
|
||||
- Use the verbosity level to filter out unnecessary details and focus on the crux of the issue.
|
||||
|
||||
This systematic and structured approach greatly simplifies the debugging process, making system maintenance more efficient.
|
||||
|
||||
### Conclusion
|
||||
|
||||
OpenIM's logging system is a testament to the importance of structured and detailed logging in complex projects. By using this logging mechanism, developers and system administrators can streamline troubleshooting and ensure the seamless operation of the OpenIM project.
|
||||
129
docs/contrib/cicd-actions.md
Normal file
129
docs/contrib/cicd-actions.md
Normal file
@@ -0,0 +1,129 @@
|
||||
# Continuous Integration and Automation
|
||||
|
||||
Every change on the OpenIM repository, either made through a pull request or direct push, triggers the continuous integration pipelines defined within the same repository. Needless to say, all the OpenIM contributions can be merged until all the checks pass (AKA having green builds).
|
||||
|
||||
- [Continuous Integration and Automation](#continuous-integration-and-automation)
|
||||
- [CI Platforms](#ci-platforms)
|
||||
- [GitHub Actions](#github-actions)
|
||||
- [Running locally](#running-locally)
|
||||
|
||||
## CI Platforms
|
||||
|
||||
Currently, there are two different platforms involved in running the CI processes:
|
||||
|
||||
- GitHub actions
|
||||
- Drone pipelines on CNCF infrastructure
|
||||
|
||||
### GitHub Actions
|
||||
|
||||
All the existing GitHub Actions are defined as YAML files under the `.github/workflows` directory. These can be grouped into:
|
||||
|
||||
- **PR Checks**. These actions run all the required validations upon PR creation and update. Covering the DCO compliance check, `x86_64` test batteries (unit, integration, smoke), and code coverage.
|
||||
- **Repository automation**. Currently, it only covers issues and epic grooming.
|
||||
|
||||
Everything runs on GitHub's provided runners; thus, the tests are limited to run in `x86_64` architectures.
|
||||
|
||||
|
||||
## Running locally
|
||||
|
||||
A contributor should verify their changes locally to speed up the pull request process. Fortunately, all the CI steps can be on local environments, except for the publishing ones, through either of the following methods:
|
||||
|
||||
**User Makefile:**
|
||||
```bash
|
||||
root@PS2023EVRHNCXG:~/workspaces/openim/Open-IM-Server# make help 😊
|
||||
|
||||
Usage: make <TARGETS> <OPTIONS> ...
|
||||
|
||||
Targets:
|
||||
|
||||
all Run tidy, gen, add-copyright, format, lint, cover, build 🚀
|
||||
build Build binaries by default 🛠️
|
||||
multiarch Build binaries for multiple platforms. See option PLATFORMS. 🌍
|
||||
tidy tidy go.mod ✨
|
||||
vendor vendor go.mod 📦
|
||||
style code style -> fmt,vet,lint 💅
|
||||
fmt Run go fmt against code. ✨
|
||||
vet Run go vet against code. ✅
|
||||
lint Check syntax and styling of go sources. ✔️
|
||||
format Gofmt (reformat) package sources (exclude vendor dir if existed). 🔄
|
||||
test Run unit test. 🧪
|
||||
cover Run unit test and get test coverage. 📊
|
||||
updates Check for updates to go.mod dependencies 🆕
|
||||
imports task to automatically handle import packages in Go files using goimports tool 📥
|
||||
clean Remove all files that are created by building. 🗑️
|
||||
image Build docker images for host arch. 🐳
|
||||
image.multiarch Build docker images for multiple platforms. See option PLATFORMS. 🌍🐳
|
||||
push Build docker images for host arch and push images to registry. 📤🐳
|
||||
push.multiarch Build docker images for multiple platforms and push images to registry. 🌍📤🐳
|
||||
tools Install dependent tools. 🧰
|
||||
gen Generate all necessary files. 🧩
|
||||
swagger Generate swagger document. 📖
|
||||
serve-swagger Serve swagger spec and docs. 🚀📚
|
||||
verify-copyright Verify the license headers for all files. ✅
|
||||
add-copyright Add copyright ensure source code files have license headers. 📄
|
||||
release release the project 🎉
|
||||
help Show this help info. ℹ️
|
||||
help-all Show all help details info. ℹ️📚
|
||||
|
||||
Options:
|
||||
|
||||
DEBUG Whether or not to generate debug symbols. Default is 0. ❓
|
||||
|
||||
BINS Binaries to build. Default is all binaries under cmd. 🛠️
|
||||
This option is available when using: make {build}(.multiarch) 🧰
|
||||
Example: make build BINS="openim-api openim_cms_api".
|
||||
|
||||
PLATFORMS Platform to build for. Default is linux_arm64 and linux_amd64. 🌍
|
||||
This option is available when using: make {build}.multiarch 🌍
|
||||
Example: make multiarch PLATFORMS="linux_s390x linux_mips64
|
||||
linux_mips64le darwin_amd64 windows_amd64 linux_amd64 linux_arm64".
|
||||
|
||||
V Set to 1 enable verbose build. Default is 0. 📝
|
||||
```
|
||||
|
||||
|
||||
How to Use Makefile to Help Contributors Build Projects Quickly 😊
|
||||
|
||||
The `make help` command is a handy tool that provides useful information on how to utilize the Makefile effectively. By running this command, contributors will gain insights into various targets and options available for building projects swiftly.
|
||||
|
||||
Here's a breakdown of the targets and options provided by the Makefile:
|
||||
|
||||
**Targets 😃**
|
||||
|
||||
1. `all`: This target runs multiple tasks like `tidy`, `gen`, `add-copyright`, `format`, `lint`, `cover`, and `build`. It ensures comprehensive project building.
|
||||
2. `build`: The primary target that compiles binaries by default. It is particularly useful for creating the necessary executable files.
|
||||
3. `multiarch`: A target that builds binaries for multiple platforms. Contributors can specify the desired platforms using the `PLATFORMS` option.
|
||||
4. `tidy`: This target cleans up the `go.mod` file, ensuring its consistency.
|
||||
5. `vendor`: A target that updates the project dependencies based on the `go.mod` file.
|
||||
6. `style`: Checks the code style using tools like `fmt`, `vet`, and `lint`. It ensures a consistent coding style throughout the project.
|
||||
7. `fmt`: Formats the code using the `go fmt` command, ensuring proper indentation and formatting.
|
||||
8. `vet`: Runs the `go vet` command to identify common errors in the code.
|
||||
9. `lint`: Validates the syntax and styling of Go source files using a linter.
|
||||
10. `format`: Reformats the package sources using `gofmt`. It excludes the vendor directory if it exists.
|
||||
11. `test`: Executes unit tests to ensure the functionality and stability of the code.
|
||||
12. `cover`: Performs unit tests and calculates the test coverage of the code.
|
||||
13. `updates`: Checks for updates to the project's dependencies specified in the `go.mod` file.
|
||||
14. `imports`: Automatically handles import packages in Go files using the `goimports` tool.
|
||||
15. `clean`: Removes all files generated during the build process, effectively cleaning up the project directory.
|
||||
16. `image`: Builds Docker images for the host architecture.
|
||||
17. `image.multiarch`: Similar to the `image` target, but it builds Docker images for multiple platforms. Contributors can specify the desired platforms using the `PLATFORMS` option.
|
||||
18. `push`: Builds Docker images for the host architecture and pushes them to a registry.
|
||||
19. `push.multiarch`: Builds Docker images for multiple platforms and pushes them to a registry. Contributors can specify the desired platforms using the `PLATFORMS` option.
|
||||
20. `tools`: Installs the necessary tools or dependencies required by the project.
|
||||
21. `gen`: Generates all the required files automatically.
|
||||
22. `swagger`: Generates the swagger document for the project.
|
||||
23. `serve-swagger`: Serves the swagger specification and documentation.
|
||||
24. `verify-copyright`: Verifies the license headers for all project files.
|
||||
25. `add-copyright`: Adds copyright headers to the source code files.
|
||||
26. `release`: Releases the project, presumably for distribution.
|
||||
27. `help`: Displays information about available targets and options.
|
||||
28. `help-all`: Shows detailed information about all available targets and options.
|
||||
|
||||
**Options 😄**
|
||||
|
||||
1. `DEBUG`: A boolean option that determines whether or not to generate debug symbols. The default value is 0 (false).
|
||||
2. `BINS`: Specifies the binaries to build. By default, it builds all binaries under the `cmd` directory. Contributors can provide a list of specific binaries using this option.
|
||||
3. `PLATFORMS`: Specifies the platforms to build for. The default platforms are `linux_arm64` and `linux_amd64`. Contributors can specify multiple platforms by providing a space-separated list of platform names.
|
||||
4. `V`: A boolean option that enables verbose build output when set to 1 (true). The default value is 0 (false).
|
||||
|
||||
With these targets and options in place, contributors can efficiently build projects using the Makefile. Happy coding! 🚀😊
|
||||
88
docs/contrib/code-conventions.md
Normal file
88
docs/contrib/code-conventions.md
Normal file
@@ -0,0 +1,88 @@
|
||||
# Code conventions
|
||||
|
||||
- [Code conventions](#code-conventions)
|
||||
- [POSIX shell](#posix-shell)
|
||||
- [Go](#go)
|
||||
- [OpenIM Naming Conventions Guide](#openim-naming-conventions-guide)
|
||||
- [1. General File Naming](#1-general-file-naming)
|
||||
- [2. Special File Types](#2-special-file-types)
|
||||
- [a. Script and Markdown Files](#a-script-and-markdown-files)
|
||||
- [b. Uppercase Markdown Documentation](#b-uppercase-markdown-documentation)
|
||||
- [3. Directory Naming](#3-directory-naming)
|
||||
- [4. Configuration Files](#4-configuration-files)
|
||||
- [Best Practices](#best-practices)
|
||||
- [Directory and File Conventions](#directory-and-file-conventions)
|
||||
- [Testing conventions](#testing-conventions)
|
||||
|
||||
## POSIX shell
|
||||
|
||||
- [Style guide](https://google.github.io/styleguide/shell.xml)
|
||||
|
||||
## Go
|
||||
|
||||
- [Go Code Review Comments](https://github.com/golang/go/wiki/CodeReviewComments)
|
||||
- [Effective Go](https://golang.org/doc/effective_go.html)
|
||||
- Know and avoid [Go landmines](https://gist.github.com/lavalamp/4bd23295a9f32706a48f)
|
||||
- Comment your code.
|
||||
- [Go's commenting conventions](http://blog.golang.org/godoc-documenting-go-code)
|
||||
- If reviewers ask questions about why the code is the way it is, that's a sign that comments might be helpful.
|
||||
- Command-line flags should use dashes, not underscores
|
||||
- Naming
|
||||
- Please consider package name when selecting an interface name, and avoid redundancy. For example, `storage.Interface` is better than `storage.StorageInterface`.
|
||||
- Do not use uppercase characters, underscores, or dashes in package names.
|
||||
- Please consider parent directory name when choosing a package name. For example, `pkg/controllers/autoscaler/foo.go` should say `package autoscaler` not `package autoscalercontroller`.
|
||||
- Unless there's a good reason, the `package foo` line should match the name of the directory in which the `.go` file exists.
|
||||
- Importers can use a different name if they need to disambiguate.Ⓜ️
|
||||
|
||||
## OpenIM Naming Conventions Guide
|
||||
|
||||
Welcome to the OpenIM Naming Conventions Guide. This document outlines the best practices and standardized naming conventions that our project follows to maintain clarity, consistency, and alignment with industry standards, specifically taking cues from the Google Naming Conventions.
|
||||
|
||||
### 1. General File Naming
|
||||
|
||||
Files within the OpenIM project should adhere to the following rules:
|
||||
|
||||
+ Both hyphens (`-`) and underscores (`_`) are acceptable in file names.
|
||||
+ Underscores (`_`) are preferred for general files to enhance readability and compatibility.
|
||||
+ For example: `data_processor.py`, `user_profile_generator.go`
|
||||
|
||||
### 2. Special File Types
|
||||
|
||||
#### a. Script and Markdown Files
|
||||
|
||||
+ Bash scripts and Markdown files should use hyphens (`-`) to facilitate better searchability and compatibility in web browsers.
|
||||
+ For example: `deploy-script.sh`, `project-overview.md`
|
||||
|
||||
#### b. Uppercase Markdown Documentation
|
||||
|
||||
+ Markdown files with uppercase names, such as `README`, may include underscores (`_`) to separate words if necessary.
|
||||
+ For example: `README_SETUP.md`, `CONTRIBUTING_GUIDELINES.md`
|
||||
|
||||
### 3. Directory Naming
|
||||
|
||||
+ Directories must use hyphens (`-`) exclusively to maintain a clean and organized file structure.
|
||||
+ For example: `image-assets`, `user-data`
|
||||
|
||||
### 4. Configuration Files
|
||||
|
||||
+ Configuration files, including but not limited to `.yaml` files, should use hyphens (`-`).
|
||||
+ For example: `app-config.yaml`, `logging-config.yaml`
|
||||
|
||||
### Best Practices
|
||||
|
||||
+ Keep names concise but descriptive enough to convey the file's purpose or contents at a glance.
|
||||
+ Avoid using spaces in names; use hyphens or underscores instead to improve compatibility across different operating systems and environments.
|
||||
+ Stick to lowercase naming where possible for consistency and to prevent issues with case-sensitive systems.
|
||||
+ Include version numbers or dates in file names if the file is subject to updates, following the format: `project-plan-v1.2.md` or `backup-2023-03-15.sql`.
|
||||
|
||||
## Directory and File Conventions
|
||||
|
||||
- Avoid generic utility packages. Instead of naming a package "util", choose a name that clearly describes its purpose. For instance, functions related to waiting operations are contained within the `wait` package, which includes methods like `Poll`, fully named as `wait.Poll`.
|
||||
- All filenames, script files, configuration files, and directories should be in lowercase and use dashes (`-`) as separators.
|
||||
- For Go language files, filenames should be in lowercase and use underscores (`_`).
|
||||
- Package names should match their directory names to ensure consistency. For example, within the `openim-api` directory, the Go file should be named `openim-api.go`, following the convention of using dashes for directory names and aligning package names with directory names.
|
||||
|
||||
|
||||
## Testing conventions
|
||||
|
||||
Please refer to [TESTING.md](https://github.com/openimsdk/open-im-server-deploy/tree/main/test/readme) document.
|
||||
9
docs/contrib/commit.md
Normal file
9
docs/contrib/commit.md
Normal file
@@ -0,0 +1,9 @@
|
||||
## Commit Standards
|
||||
|
||||
Our project, OpenIM, follows the [Conventional Commits](https://www.conventionalcommits.org/en/v1.0.0) standards.
|
||||
|
||||
> Chinese translation: [Conventional Commits: A Specification Making Commit Logs More Human and Machine-friendly](https://tool.lu/en_US/article/2ac/preview)
|
||||
|
||||
In addition to adhering to these standards, we encourage all contributors to the OpenIM project to ensure that their commit messages are clear and descriptive. This helps in maintaining a clean and meaningful project history. Each commit message should succinctly describe the changes made and, where necessary, the reasoning behind those changes.
|
||||
|
||||
To facilitate a streamlined process, we also recommend using appropriate commit type based on Conventional Commits guidelines such as `fix:` for bug fixes, `feat:` for new features, and so forth. Understanding and using these conventions helps in generating automatic release notes, making versioning easier, and improving overall readability of commit history.
|
||||
72
docs/contrib/development.md
Normal file
72
docs/contrib/development.md
Normal file
@@ -0,0 +1,72 @@
|
||||
# Development Guide
|
||||
|
||||
Since OpenIM is written in Go, it is fair to assume that the Go tools are all one needs to contribute to this project. Unfortunately, there is a point where this no longer holds true when required to test or build local changes. This document elaborates on the required tooling for OpenIM development.
|
||||
|
||||
- [Development Guide](#development-guide)
|
||||
- [Non-Linux environment prerequisites](#non-linux-environment-prerequisites)
|
||||
- [Windows Setup](#windows-setup)
|
||||
- [macOS Setup](#macos-setup)
|
||||
- [Installing Required Software](#installing-required-software)
|
||||
- [Go](#go)
|
||||
- [Docker](#docker)
|
||||
- [Vagrant](#vagrant)
|
||||
- [Dependency management](#dependency-management)
|
||||
|
||||
## Non-Linux environment prerequisites
|
||||
|
||||
All the test and build scripts within this repository were created to be run on GNU Linux development environments. Due to this, it is suggested to use the virtual machine defined on this repository's [Vagrantfile](https://developer.hashicorp.com/vagrant/docs/vagrantfile) to use them.
|
||||
|
||||
Either way, if one still wants to build and test OpenIM on non-Linux environments, specific setups are to be followed.
|
||||
|
||||
### Windows Setup
|
||||
|
||||
To build OpenIM on Windows is only possible for versions that support Windows Subsystem for Linux (WSL). If the development environment in question has Windows 10, Version 2004, Build 19041 or higher, [follow these instructions to install WSL2](https://docs.microsoft.com/en-us/windows/wsl/install-win10); otherwise, use a Linux Virtual machine instead.
|
||||
|
||||
### macOS Setup
|
||||
|
||||
The shell scripts in charge of the build and test processes rely on GNU utils (i.e. `sed`), [which slightly differ on macOS](https://unix.stackexchange.com/a/79357), meaning that one must make some adjustments before using them.
|
||||
|
||||
First, install the GNU utils:
|
||||
|
||||
```sh
|
||||
brew install coreutils findutils gawk gnu-sed gnu-tar grep make
|
||||
```
|
||||
|
||||
Then update the shell init script (i.e. `.bashrc`) to prepend the GNU Utils to the `$PATH` variable
|
||||
|
||||
```sh
|
||||
GNUBINS="$(find /usr/local/opt -type d -follow -name gnubin -print)"
|
||||
|
||||
for bindir in ${GNUBINS[@]}; do
|
||||
PATH=$bindir:$PATH
|
||||
done
|
||||
|
||||
export PATH
|
||||
```
|
||||
|
||||
## Installing Required Software
|
||||
|
||||
### Go
|
||||
|
||||
It is well known that OpenIM is written in [Go](http://golang.org). Please follow the [Go Getting Started guide](https://golang.org/doc/install) to install and set up the Go tools used to compile and run the test batteries.
|
||||
|
||||
| OpenIM | requires Go |
|
||||
|----------------|-------------|
|
||||
| 2.24 - 3.00 | 1.15 + |
|
||||
| 3.30 + | 1.18 + |
|
||||
|
||||
### Docker
|
||||
|
||||
OpenIM build and test processes development require Docker to run certain steps. [Follow the Docker website instructions to install Docker](https://docs.docker.com/get-docker/) in the development environment.
|
||||
|
||||
### Vagrant
|
||||
|
||||
As described in the [Testing documentation](https://github.com/openimsdk/open-im-server-deploy/tree/main/test/readme), all the smoke tests are run in virtual machines managed by Vagrant. To install Vagrant in the development environment, [follow the instructions from the Hashicorp website](https://www.vagrantup.com/downloads), alongside any of the following hypervisors:
|
||||
|
||||
- [VirtualBox](https://www.virtualbox.org/)
|
||||
- [libvirt](https://libvirt.org/) and the [vagrant-libvirt plugin](https://github.com/vagrant-libvirt/vagrant-libvirt#installation)
|
||||
|
||||
|
||||
## Dependency management
|
||||
|
||||
OpenIM uses [go modules](https://github.com/golang/go/wiki/Modules) to manage dependencies.
|
||||
3
docs/contrib/directory.md
Normal file
3
docs/contrib/directory.md
Normal file
@@ -0,0 +1,3 @@
|
||||
## Catalog Service Interface Specification
|
||||
|
||||
+ [https://github.com/kubecub/go-project-layout](https://github.com/kubecub/go-project-layout)
|
||||
537
docs/contrib/environment.md
Normal file
537
docs/contrib/environment.md
Normal file
@@ -0,0 +1,537 @@
|
||||
# OpenIM ENVIRONMENT CONFIGURATION
|
||||
|
||||
<!-- vscode-markdown-toc -->
|
||||
* 1. [OpenIM Deployment Guide](#OpenIMDeploymentGuide)
|
||||
* 1.1. [Deployment Strategies](#DeploymentStrategies)
|
||||
* 1.2. [Source Code Deployment](#SourceCodeDeployment)
|
||||
* 1.3. [Docker Compose Deployment](#DockerComposeDeployment)
|
||||
* 1.4. [Environment Variable Configuration](#EnvironmentVariableConfiguration)
|
||||
* 1.4.1. [Recommended using environment variables](#Recommendedusingenvironmentvariables)
|
||||
* 1.4.2. [Additional Configuration](#AdditionalConfiguration)
|
||||
* 1.4.3. [Security Considerations](#SecurityConsiderations)
|
||||
* 1.4.4. [Data Management](#DataManagement)
|
||||
* 1.4.5. [Monitoring and Logging](#MonitoringandLogging)
|
||||
* 1.4.6. [Troubleshooting](#Troubleshooting)
|
||||
* 1.4.7. [Conclusion](#Conclusion)
|
||||
* 1.4.8. [Additional Resources](#AdditionalResources)
|
||||
* 2. [Further Configuration](#FurtherConfiguration)
|
||||
* 2.1. [Image Registry Configuration](#ImageRegistryConfiguration)
|
||||
* 2.2. [OpenIM Docker Network Configuration](#OpenIMDockerNetworkConfiguration)
|
||||
* 2.3. [OpenIM Configuration](#OpenIMConfiguration)
|
||||
* 2.4. [OpenIM Chat Configuration](#OpenIMChatConfiguration)
|
||||
* 2.5. [Zookeeper Configuration](#ZookeeperConfiguration)
|
||||
* 2.6. [MySQL Configuration](#MySQLConfiguration)
|
||||
* 2.7. [MongoDB Configuration](#MongoDBConfiguration)
|
||||
* 2.8. [Tencent Cloud COS Configuration](#TencentCloudCOSConfiguration)
|
||||
* 2.9. [Alibaba Cloud OSS Configuration](#AlibabaCloudOSSConfiguration)
|
||||
* 2.10. [Redis Configuration](#RedisConfiguration)
|
||||
* 2.11. [Kafka Configuration](#KafkaConfiguration)
|
||||
* 2.12. [OpenIM Web Configuration](#OpenIMWebConfiguration)
|
||||
* 2.13. [RPC Configuration](#RPCConfiguration)
|
||||
* 2.14. [Prometheus Configuration](#PrometheusConfiguration)
|
||||
* 2.15. [Grafana Configuration](#GrafanaConfiguration)
|
||||
* 2.16. [RPC Port Configuration Variables](#RPCPortConfigurationVariables)
|
||||
* 2.17. [RPC Register Name Configuration](#RPCRegisterNameConfiguration)
|
||||
* 2.18. [Log Configuration](#LogConfiguration)
|
||||
* 2.19. [Additional Configuration Variables](#AdditionalConfigurationVariables)
|
||||
* 2.20. [Prometheus Configuration](#PrometheusConfiguration-1)
|
||||
* 2.20.1. [General Configuration](#GeneralConfiguration)
|
||||
* 2.20.2. [Service-Specific Prometheus Ports](#Service-SpecificPrometheusPorts)
|
||||
* 2.21. [Qiniu Cloud Kodo Configuration](#QiniuCloudKODOConfiguration)
|
||||
|
||||
## 0. <a name='TableofContents'></a>OpenIM Config File
|
||||
|
||||
Ensuring that OpenIM operates smoothly requires clear direction on the configuration file's location. Here's a detailed step-by-step guide on how to provide this essential path to OpenIM:
|
||||
|
||||
1. **Using the Command-line Argument**:
|
||||
|
||||
+ **For Configuration Path**: When initializing OpenIM, you can specify the path to the configuration file directly using the `-c` or `--config_folder_path` option.
|
||||
|
||||
```bash
|
||||
❯ _output/bin/platforms/linux/amd64/openim-api --config_folder_path="/your/config/folder/path"
|
||||
```
|
||||
|
||||
+ **For Port Specification**: Similarly, if you wish to designate a particular port, utilize the `-p` option followed by the desired port number.
|
||||
|
||||
```bash
|
||||
❯ _output/bin/platforms/linux/amd64/openim-api -p 1234
|
||||
```
|
||||
|
||||
Note: If the port is not specified here, OpenIM will fetch it from the configuration file. Setting the port via environment variables isn't supported. We recommend consolidating settings in the configuration file for a more consistent and streamlined setup.
|
||||
|
||||
2. **Leveraging the Environment Variable**:
|
||||
|
||||
You have the flexibility to determine OpenIM's configuration path by setting an `OPENIMCONFIG` environment variable. This method provides a seamless way to instruct OpenIM without command-line parameters every time.
|
||||
|
||||
```bash
|
||||
export OPENIMCONFIG="/path/to/your/config"
|
||||
```
|
||||
|
||||
3. **Relying on the Default Path**:
|
||||
|
||||
In scenarios where neither command-line arguments nor environment variables are provided, OpenIM will intuitively revert to the `config/` directory to locate its configuration.
|
||||
|
||||
|
||||
|
||||
## 1. <a name='OpenIMDeploymentGuide'></a>OpenIM Deployment Guide
|
||||
|
||||
Welcome to the OpenIM Deployment Guide! OpenIM offers a versatile and robust instant messaging server, and deploying it can be achieved through various methods. This guide will walk you through the primary deployment strategies, ensuring you can set up OpenIM in a way that best suits your needs.
|
||||
|
||||
### 1.1. <a name='DeploymentStrategies'></a>Deployment Strategies
|
||||
|
||||
OpenIM provides multiple deployment methods, each tailored to different use cases and technical preferences:
|
||||
|
||||
1. **[Source Code Deployment Guide](https://doc.rentsoft.cn/guides/gettingStarted/imSourceCodeDeployment)**
|
||||
2. **[Docker Deployment Guide](https://doc.rentsoft.cn/guides/gettingStarted/dockerCompose)**
|
||||
3. **[Kubernetes Deployment Guide](https://github.com/openimsdk/open-im-server-deploy/tree/main/deployments)**
|
||||
|
||||
While the first two methods will be our main focus, it's worth noting that the third method, Kubernetes deployment, is also viable and can be rendered via the `environment.sh` script variables.
|
||||
|
||||
### 1.2. <a name='SourceCodeDeployment'></a>Source Code Deployment
|
||||
|
||||
In the source code deployment method, the configuration generation process involves executing `make init`, which fundamentally runs the script `./scripts/init-config.sh`. This script utilizes variables defined in the [`environment.sh`](https://github.com/openimsdk/open-im-server-deploy/blob/main/scripts/install/environment.sh) script to render the [`config.yaml`](https://github.com/openimsdk/open-im-server-deploy/blob/main/deployments/templates/config.yaml) template file, subsequently generating the [`config.yaml`](https://github.com/openimsdk/open-im-server-deploy/blob/main/config/config.yaml) configuration file.
|
||||
|
||||
### 1.3. <a name='DockerComposeDeployment'></a>Docker Compose Deployment
|
||||
|
||||
Docker deployment offers a slightly more intricate template. Within the [openim-server](https://github.com/openimsdk/openim-docker/tree/main/openim-server) directory, multiple subdirectories correspond to various versions, each aligning with `openim-chat` as illustrated below:
|
||||
|
||||
| openim-server | openim-chat |
|
||||
| ------------------------------------------------------------ | ------------------------------------------------------------ |
|
||||
| [main](https://github.com/openimsdk/openim-docker/tree/main/openim-server/main) | [main](https://github.com/openimsdk/openim-docker/tree/main/openim-chat/main) |
|
||||
| [release-v3.2](https://github.com/openimsdk/openim-docker/tree/main/openim-server/release-v3.3) | [release-v3.2](https://github.com/openimsdk/openim-docker/tree/main/openim-chat/release-v1.3) |
|
||||
| [release-v3.2](https://github.com/openimsdk/openim-docker/tree/main/openim-server/release-v3.2) | [release-v3.2](https://github.com/openimsdk/openim-docker/tree/main/openim-chat/release-v1.2) |
|
||||
|
||||
Configuration file modifications can be made by specifying corresponding environment variables, for instance:
|
||||
|
||||
```bash
|
||||
export CHAT_IMAGE_VERSION="main"
|
||||
export SERVER_IMAGE_VERSION="main"
|
||||
```
|
||||
|
||||
These variables are stored within the [`environment.sh`](https://github.com/OpenIMSDK/open-im-server-deploy/blob/main/scripts/install/environment.sh) configuration:
|
||||
|
||||
```bash
|
||||
readonly CHAT_IMAGE_VERSION=${CHAT_IMAGE_VERSION:-'main'}
|
||||
readonly SERVER_IMAGE_VERSION=${SERVER_IMAGE_VERSION:-'main'}
|
||||
```
|
||||
> [!IMPORTANT]
|
||||
> Can learn to read our mirror version strategy: https://github.com/openimsdk/open-im-server-deploy/blob/main/docs/contrib/images.md
|
||||
|
||||
|
||||
Setting a variable, e.g., `export CHAT_IMAGE_VERSION="release-v1.3"`, will prioritize `CHAT_IMAGE_VERSION="release-v1.3"` as the variable value. Ultimately, the chosen image version is determined, and rendering is achieved through `make init` (or `./scripts/init-config.sh`).
|
||||
|
||||
> Note: Direct modifications to the `config.yaml` file are also permissible without utilizing `make init`.
|
||||
|
||||
### 1.4. <a name='EnvironmentVariableConfiguration'></a>Environment Variable Configuration
|
||||
|
||||
For convenience, configuration through modifying environment variables is recommended:
|
||||
|
||||
#### 1.4.1. <a name='Recommendedusingenvironmentvariables'></a>Recommended using environment variables
|
||||
|
||||
+ PASSWORD
|
||||
|
||||
+ **Description**: Password for mongodb, redis, and minio.
|
||||
+ **Default**: `openIM123`
|
||||
+ Notes:
|
||||
+ Minimum password length: 8 characters.
|
||||
+ Special characters are not allowed.
|
||||
|
||||
```bash
|
||||
export PASSWORD="openIM123"
|
||||
```
|
||||
|
||||
+ OPENIM_USER
|
||||
|
||||
+ **Description**: Username for redis, and minio.
|
||||
+ **Default**: `root`
|
||||
|
||||
```bash
|
||||
export OPENIM_USER="root"
|
||||
```
|
||||
|
||||
> mongo is `openIM`, use `export MONGO_OPENIM_USERNAME="openIM"` to modify
|
||||
|
||||
+ OPENIM_IP
|
||||
|
||||
+ **Description**: API address.
|
||||
+ **Note**: If the server has an external IP, it will be automatically obtained. For internal networks, set this variable to the IP serving internally.
|
||||
|
||||
```bash
|
||||
export OPENIM_IP="ip"
|
||||
```
|
||||
|
||||
+ DATA_DIR
|
||||
|
||||
+ **Description**: Data mount directory for components.
|
||||
+ **Default**: `/data/openim`
|
||||
|
||||
```bash
|
||||
export DATA_DIR="/data/openim"
|
||||
```
|
||||
|
||||
#### 1.4.2. <a name='AdditionalConfiguration'></a>Additional Configuration
|
||||
|
||||
##### MinIO Access and Secret Key
|
||||
|
||||
To secure your MinIO server, you should set up an access key and secret key. These credentials are used to authenticate requests to your MinIO server.
|
||||
|
||||
```bash
|
||||
export MINIO_ACCESS_KEY="YourAccessKey"
|
||||
export MINIO_SECRET_KEY="YourSecretKey"
|
||||
```
|
||||
|
||||
##### MinIO Browser
|
||||
|
||||
MinIO comes with an embedded web-based object browser. You can control the availability of the MinIO browser by setting the `MINIO_BROWSER` environment variable.
|
||||
|
||||
```bash
|
||||
export MINIO_BROWSER="on"
|
||||
```
|
||||
|
||||
#### 1.4.3. <a name='SecurityConsiderations'></a>Security Considerations
|
||||
|
||||
##### TLS/SSL Configuration
|
||||
|
||||
For secure communication, it's recommended to enable TLS/SSL for your MinIO server. You can do this by providing the path to the SSL certificate and key files.
|
||||
|
||||
```bash
|
||||
export MINIO_CERTS_DIR="/path/to/certs/directory"
|
||||
```
|
||||
|
||||
#### 1.4.4. <a name='DataManagement'></a>Data Management
|
||||
|
||||
##### Data Retention Policy
|
||||
|
||||
You may want to set up a data retention policy to automatically delete objects after a specified period.
|
||||
|
||||
```bash
|
||||
export MINIO_RETENTION_DAYS="30"
|
||||
```
|
||||
|
||||
#### 1.4.5. <a name='MonitoringandLogging'></a>Monitoring and Logging
|
||||
|
||||
##### [Audit Logging](https://github.com/openimsdk/open-im-server-deploy/blob/main/docs/contrib/environment.md#audit-logging)
|
||||
|
||||
Enable audit logging to keep track of access and changes to your data.
|
||||
|
||||
```bash
|
||||
export MINIO_AUDIT="on"
|
||||
```
|
||||
|
||||
#### 1.4.6. <a name='Troubleshooting'></a>Troubleshooting
|
||||
|
||||
##### Debug Mode
|
||||
|
||||
In case of issues, you may enable debug mode to get more detailed logs to assist in troubleshooting.
|
||||
|
||||
```bash
|
||||
export MINIO_DEBUG="on"
|
||||
```
|
||||
|
||||
#### 1.4.7. <a name='Conclusion'></a>Conclusion
|
||||
|
||||
With the environment variables configured as per your requirements, your MinIO server should be ready to securely store and manage your object data. Ensure to verify the setup and monitor the logs for any unusual activities or errors. Regularly update the MinIO server and review your configuration to adapt to any changes or improvements in the MinIO system.
|
||||
|
||||
#### 1.4.8. <a name='AdditionalResources'></a>Additional Resources
|
||||
|
||||
+ [MinIO Client Quickstart Guide](https://docs.min.io/docs/minio-client-quickstart-guide)
|
||||
+ [MinIO Admin Complete Guide](https://docs.min.io/docs/minio-admin-complete-guide)
|
||||
+ [MinIO Docker Quickstart Guide](https://docs.min.io/docs/minio-docker-quickstart-guide)
|
||||
|
||||
Feel free to explore the MinIO documentation for more advanced configurations and usage scenarios.
|
||||
|
||||
|
||||
|
||||
## 2. <a name='FurtherConfiguration'></a>Further Configuration
|
||||
|
||||
### 2.1. <a name='ImageRegistryConfiguration'></a>Image Registry Configuration
|
||||
|
||||
**Description**: The image registry configuration allows users to select an image address for use. The default is set to use GITHUB images, but users can opt for Docker Hub or Ali Cloud, especially beneficial for Chinese users due to its local proximity.
|
||||
|
||||
| Parameter | Default Value | Description |
|
||||
| ---------------- | --------------------- | ------------------------------------------------------------ |
|
||||
| `IMAGE_REGISTRY` | `"ghcr.io/openimsdk"` | The registry from which Docker images will be pulled. Other options include `"openim"` and `"registry.cn-hangzhou.aliyuncs.com/openimsdk"`. |
|
||||
|
||||
### 2.2. <a name='OpenIMDockerNetworkConfiguration'></a>OpenIM Docker Network Configuration
|
||||
|
||||
**Description**: This section configures the Docker network subnet and generates IP addresses for various services within the defined subnet.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| --------------------------- | ----------------- | ------------------------------------------------------------ |
|
||||
| `DOCKER_BRIDGE_SUBNET` | `'172.28.0.0/16'` | The subnet for the Docker network. |
|
||||
| `DOCKER_BRIDGE_GATEWAY` | Generated IP | The gateway IP address within the Docker subnet. |
|
||||
| `[SERVICE]_NETWORK_ADDRESS` | Generated IP | The network IP address for a specific service (e.g., MYSQL, MONGO, REDIS, etc.) within the Docker subnet. |
|
||||
|
||||
### 2.3. <a name='OpenIMConfiguration'></a>OpenIM Configuration
|
||||
|
||||
**Description**: OpenIM configuration involves setting up directories for data, installation, configuration, and logs. It also involves configuring the OpenIM server address and ports for WebSocket and API.
|
||||
|
||||
| Parameter | Default Value | Description |
|
||||
| ----------------------- | ------------------------ | ----------------------------------------- |
|
||||
| `OPENIM_DATA_DIR` | `"/data/openim"` | Directory for OpenIM data. |
|
||||
| `OPENIM_INSTALL_DIR` | `"/opt/openim"` | Directory where OpenIM is installed. |
|
||||
| `OPENIM_CONFIG_DIR` | `"/etc/openim"` | Directory for OpenIM configuration files. |
|
||||
| `OPENIM_LOG_DIR` | `"/var/log/openim"` | Directory for OpenIM logs. |
|
||||
| `OPENIM_SERVER_ADDRESS` | Docker Bridge Gateway IP | OpenIM server address. |
|
||||
| `OPENIM_WS_PORT` | `'10001'` | Port for OpenIM WebSocket. |
|
||||
| `API_OPENIM_PORT` | `'10002'` | Port for OpenIM API. |
|
||||
|
||||
### 2.4. <a name='OpenIMChatConfiguration'></a>OpenIM Chat Configuration
|
||||
|
||||
**Description**: Configuration for OpenIM chat, including data directory, server address, and ports for API and chat functionalities.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| ----------------------- | -------------------------- | ------------------------------- |
|
||||
| `OPENIM_CHAT_DATA_DIR` | `"./openim-chat/[BRANCH]"` | Directory for OpenIM chat data. |
|
||||
| `OPENIM_CHAT_ADDRESS` | Docker Bridge Gateway IP | OpenIM chat service address. |
|
||||
| `OPENIM_CHAT_API_PORT` | `"10008"` | Port for OpenIM chat API. |
|
||||
| `OPENIM_ADMIN_API_PORT` | `"10009"` | Port for OpenIM Admin API. |
|
||||
| `OPENIM_ADMIN_PORT` | `"30200"` | Port for OpenIM chat Admin. |
|
||||
| `OPENIM_CHAT_PORT` | `"30300"` | Port for OpenIM chat. |
|
||||
|
||||
### 2.5. <a name='ZookeeperConfiguration'></a>Zookeeper Configuration
|
||||
|
||||
**Description**: Configuration for Zookeeper, including schema, port, address, and credentials.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| -------------------- | ------------------------ | ----------------------- |
|
||||
| `ZOOKEEPER_SCHEMA` | `"openim"` | Schema for Zookeeper. |
|
||||
| `ZOOKEEPER_PORT` | `"12181"` | Port for Zookeeper. |
|
||||
| `ZOOKEEPER_ADDRESS` | Docker Bridge Gateway IP | Address for Zookeeper. |
|
||||
| `ZOOKEEPER_USERNAME` | `""` | Username for Zookeeper. |
|
||||
| `ZOOKEEPER_PASSWORD` | `""` | Password for Zookeeper. |
|
||||
|
||||
### 2.7. <a name='MongoDBConfiguration'></a>MongoDB Configuration
|
||||
|
||||
This section involves setting up MongoDB, including its port, address, and credentials.
|
||||
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| -------------- | -------------- | ----------------------- |
|
||||
| MONGO_PORT | "27017" | Port used by MongoDB. |
|
||||
| MONGO_ADDRESS | [Generated IP] | IP address for MongoDB. |
|
||||
| MONGO_USERNAME | [User Defined] | Admin Username for MongoDB. |
|
||||
| MONGO_PASSWORD | [User Defined] | Admin Password for MongoDB. |
|
||||
| MONGO_OPENIM_USERNAME | [User Defined] | OpenIM Username for MongoDB. |
|
||||
| MONGO_OPENIM_PASSWORD | [User Defined] | OpenIM Password for MongoDB. |
|
||||
|
||||
### 2.8. <a name='TencentCloudCOSConfiguration'></a>Tencent Cloud COS Configuration
|
||||
|
||||
This section involves setting up Tencent Cloud COS, including its bucket URL and credentials.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| ----------------- | ------------------------------------------------------------ | ------------------------------------ |
|
||||
| COS_BUCKET_URL | "[https://temp-1252357374.cos.ap-chengdu.myqcloud.com](https://temp-1252357374.cos.ap-chengdu.myqcloud.com/)" | Tencent Cloud COS bucket URL. |
|
||||
| COS_SECRET_ID | [User Defined] | Secret ID for Tencent Cloud COS. |
|
||||
| COS_SECRET_KEY | [User Defined] | Secret key for Tencent Cloud COS. |
|
||||
| COS_SESSION_TOKEN | [User Defined] | Session token for Tencent Cloud COS. |
|
||||
| COS_PUBLIC_READ | "false" | Public read access. |
|
||||
|
||||
### 2.9. <a name='AlibabaCloudOSSConfiguration'></a>Alibaba Cloud OSS Configuration
|
||||
|
||||
This section involves setting up Alibaba Cloud OSS, including its endpoint, bucket name, and credentials.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| --------------------- | ------------------------------------------------------------ | ---------------------------------------- |
|
||||
| OSS_ENDPOINT | "[https://oss-cn-chengdu.aliyuncs.com](https://oss-cn-chengdu.aliyuncs.com/)" | Endpoint URL for Alibaba Cloud OSS. |
|
||||
| OSS_BUCKET | "demo-9999999" | Bucket name for Alibaba Cloud OSS. |
|
||||
| OSS_BUCKET_URL | "[https://demo-9999999.oss-cn-chengdu.aliyuncs.com](https://demo-9999999.oss-cn-chengdu.aliyuncs.com/)" | Bucket URL for Alibaba Cloud OSS. |
|
||||
| OSS_ACCESS_KEY_ID | [User Defined] | Access key ID for Alibaba Cloud OSS. |
|
||||
| OSS_ACCESS_KEY_SECRET | [User Defined] | Access key secret for Alibaba Cloud OSS. |
|
||||
| OSS_SESSION_TOKEN | [User Defined] | Session token for Alibaba Cloud OSS. |
|
||||
| OSS_PUBLIC_READ | "false" | Public read access. |
|
||||
|
||||
### 2.10. <a name='RedisConfiguration'></a>Redis Configuration
|
||||
|
||||
This section involves setting up Redis, including its port, address, and credentials.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| -------------- | -------------------------- | --------------------- |
|
||||
| REDIS_PORT | "16379" | Port used by Redis. |
|
||||
| REDIS_ADDRESS | "${DOCKER_BRIDGE_GATEWAY}" | IP address for Redis. |
|
||||
| REDIS_USERNAME | [User Defined] | Username for Redis. |
|
||||
| REDIS_PASSWORD | "${PASSWORD}" | Password for Redis. |
|
||||
|
||||
### 2.11. <a name='KafkaConfiguration'></a>Kafka Configuration
|
||||
|
||||
This section involves setting up Kafka, including its port, address, credentials, and topics.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| ---------------------------- | -------------------------- | ----------------------------------- |
|
||||
| KAFKA_USERNAME | [User Defined] | Username for Kafka. |
|
||||
| KAFKA_PASSWORD | [User Defined] | Password for Kafka. |
|
||||
| KAFKA_PORT | "19094" | Port used by Kafka. |
|
||||
| KAFKA_ADDRESS | "${DOCKER_BRIDGE_GATEWAY}" | IP address for Kafka. |
|
||||
| KAFKA_LATESTMSG_REDIS_TOPIC | "latestMsgToRedis" | Topic for latest message to Redis. |
|
||||
| KAFKA_OFFLINEMSG_MONGO_TOPIC | "offlineMsgToMongoMysql" | Topic for offline message to Mongo. |
|
||||
| KAFKA_MSG_PUSH_TOPIC | "msgToPush" | Topic for message to push. |
|
||||
| KAFKA_CONSUMERGROUPID_REDIS | "redis" | Consumer group ID to Redis. |
|
||||
| KAFKA_CONSUMERGROUPID_MONGO | "mongo" | Consumer group ID to Mongo. |
|
||||
| KAFKA_CONSUMERGROUPID_MYSQL | "mysql" | Consumer group ID to MySQL. |
|
||||
| KAFKA_CONSUMERGROUPID_PUSH | "push" | Consumer group ID to push. |
|
||||
|
||||
Note: Ensure to replace placeholder values (like [User Defined], `${DOCKER_BRIDGE_GATEWAY}`, and `${PASSWORD}`) with actual values before deploying the configuration.
|
||||
|
||||
|
||||
|
||||
### 2.12. <a name='OpenIMWebConfiguration'></a>OpenIM Web Configuration
|
||||
|
||||
This section involves setting up OpenIM Web, including its port, address, and dist path.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| -------------------- | -------------------------- | ------------------------- |
|
||||
| OPENIM_WEB_PORT | "11001" | Port used by OpenIM Web. |
|
||||
| OPENIM_WEB_ADDRESS | "${DOCKER_BRIDGE_GATEWAY}" | Address for OpenIM Web. |
|
||||
| OPENIM_WEB_DIST_PATH | "/app/dist" | Dist path for OpenIM Web. |
|
||||
|
||||
### 2.13. <a name='RPCConfiguration'></a>RPC Configuration
|
||||
|
||||
Configuration for RPC, including the register and listen IP.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| --------------- | -------------- | -------------------- |
|
||||
| RPC_REGISTER_IP | [User Defined] | Register IP for RPC. |
|
||||
| RPC_LISTEN_IP | "0.0.0.0" | Listen IP for RPC. |
|
||||
|
||||
### 2.14. <a name='PrometheusConfiguration'></a>Prometheus Configuration
|
||||
|
||||
Setting up Prometheus, including its port and address.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| ------------------ | -------------------------- | ------------------------ |
|
||||
| PROMETHEUS_PORT | "19090" | Port used by Prometheus. |
|
||||
| PROMETHEUS_ADDRESS | "${DOCKER_BRIDGE_GATEWAY}" | Address for Prometheus. |
|
||||
|
||||
### 2.15. <a name='GrafanaConfiguration'></a>Grafana Configuration
|
||||
|
||||
Configuration for Grafana, including its port and address.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| --------------- | -------------------------- | --------------------- |
|
||||
| GRAFANA_PORT | "13000" | Port used by Grafana. |
|
||||
| GRAFANA_ADDRESS | "${DOCKER_BRIDGE_GATEWAY}" | Address for Grafana. |
|
||||
|
||||
### 2.16. <a name='RPCPortConfigurationVariables'></a>RPC Port Configuration Variables
|
||||
|
||||
Configuration for various RPC ports. Note: For launching multiple programs, just fill in multiple ports separated by commas. Try not to have spaces.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| --------------------------- | ------------- | ----------------------------------- |
|
||||
| OPENIM_USER_PORT | '10110' | OpenIM User Service Port. |
|
||||
| OPENIM_FRIEND_PORT | '10120' | OpenIM Friend Service Port. |
|
||||
| OPENIM_MESSAGE_PORT | '10130' | OpenIM Message Service Port. |
|
||||
| OPENIM_MESSAGE_GATEWAY_PORT | '10140' | OpenIM Message Gateway Service Port |
|
||||
| OPENIM_GROUP_PORT | '10150' | OpenIM Group Service Port. |
|
||||
| OPENIM_AUTH_PORT | '10160' | OpenIM Authorization Service Port. |
|
||||
| OPENIM_PUSH_PORT | '10170' | OpenIM Push Service Port. |
|
||||
| OPENIM_CONVERSATION_PORT | '10180' | OpenIM Conversation Service Port. |
|
||||
| OPENIM_THIRD_PORT | '10190' | OpenIM Third-Party Service Port. |
|
||||
|
||||
### 2.17. <a name='RPCRegisterNameConfiguration'></a>RPC Register Name Configuration
|
||||
|
||||
This section involves setting up the RPC Register Names for various OpenIM services.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| --------------------------- | ---------------- | ----------------------------------- |
|
||||
| OPENIM_USER_NAME | "User" | OpenIM User Service Name |
|
||||
| OPENIM_FRIEND_NAME | "Friend" | OpenIM Friend Service Name |
|
||||
| OPENIM_MSG_NAME | "Msg" | OpenIM Message Service Name |
|
||||
| OPENIM_PUSH_NAME | "Push" | OpenIM Push Service Name |
|
||||
| OPENIM_MESSAGE_GATEWAY_NAME | "MessageGateway" | OpenIM Message Gateway Service Name |
|
||||
| OPENIM_GROUP_NAME | "Group" | OpenIM Group Service Name |
|
||||
| OPENIM_AUTH_NAME | "Auth" | OpenIM Authorization Service Name |
|
||||
| OPENIM_CONVERSATION_NAME | "Conversation" | OpenIM Conversation Service Name |
|
||||
| OPENIM_THIRD_NAME | "Third" | OpenIM Third-Party Service Name |
|
||||
|
||||
### 2.18. <a name='LogConfiguration'></a>Log Configuration
|
||||
|
||||
This section involves configuring the log settings, including storage location, rotation time, and log level.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| ------------------------- | ------------------------ | --------------------------------- |
|
||||
| LOG_STORAGE_LOCATION | "${OPENIM_ROOT}/_output/logs/" | Location for storing logs |
|
||||
| LOG_ROTATION_TIME | "24" | Log rotation time (in hours) |
|
||||
| LOG_REMAIN_ROTATION_COUNT | "2" | Number of log rotations to retain |
|
||||
| LOG_REMAIN_LOG_LEVEL | "6" | Log level to retain |
|
||||
| LOG_IS_STDOUT | "false" | Output log to standard output |
|
||||
| LOG_IS_JSON | "false" | Log in JSON format |
|
||||
| LOG_WITH_STACK | "false" | Include stack info in logs |
|
||||
|
||||
### 2.19. <a name='AdditionalConfigurationVariables'></a>Additional Configuration Variables
|
||||
|
||||
This section involves setting up additional configuration variables for Websocket, Push Notifications, and Chat.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
|-------------------------|-------------------|----------------------------------|
|
||||
| WEBSOCKET_MAX_CONN_NUM | "100000" | Maximum Websocket connections |
|
||||
| WEBSOCKET_MAX_MSG_LEN | "4096" | Maximum Websocket message length |
|
||||
| WEBSOCKET_TIMEOUT | "10" | Websocket timeout |
|
||||
| PUSH_ENABLE | "getui" | Push notification enable status |
|
||||
| GETUI_PUSH_URL | [Generated URL] | GeTui Push Notification URL |
|
||||
| GETUI_MASTER_SECRET | [User Defined] | GeTui Master Secret |
|
||||
| GETUI_APP_KEY | [User Defined] | GeTui Application Key |
|
||||
| GETUI_INTENT | [User Defined] | GeTui Push Intent |
|
||||
| GETUI_CHANNEL_ID | [User Defined] | GeTui Channel ID |
|
||||
| GETUI_CHANNEL_NAME | [User Defined] | GeTui Channel Name |
|
||||
| FCM_SERVICE_ACCOUNT | "x.json" | FCM Service Account |
|
||||
| JPUSH_APP_KEY | [User Defined] | JPUSH Application Key |
|
||||
| JPUSH_MASTER_SECRET | [User Defined] | JPUSH Master Secret |
|
||||
| JPUSH_PUSH_URL | [User Defined] | JPUSH Push Notification URL |
|
||||
| JPUSH_PUSH_INTENT | [User Defined] | JPUSH Push Intent |
|
||||
| IM_ADMIN_USERID | "imAdmin" | IM Administrator ID |
|
||||
| IM_ADMIN_NAME | "imAdmin" | IM Administrator Nickname |
|
||||
| MULTILOGIN_POLICY | "1" | Multi-login Policy |
|
||||
| CHAT_PERSISTENCE_MYSQL | "true" | Chat Persistence in MySQL |
|
||||
| MSG_CACHE_TIMEOUT | "86400" | Message Cache Timeout |
|
||||
| GROUP_MSG_READ_RECEIPT | "true" | Group Message Read Receipt Enable |
|
||||
| SINGLE_MSG_READ_RECEIPT | "true" | Single Message Read Receipt Enable |
|
||||
| RETAIN_CHAT_RECORDS | "365" | Retain Chat Records (in days) |
|
||||
| CHAT_RECORDS_CLEAR_TIME | [Cron Expression] | Chat Records Clear Time |
|
||||
| MSG_DESTRUCT_TIME | [Cron Expression] | Message Destruct Time |
|
||||
| SECRET | "${PASSWORD}" | Secret Key |
|
||||
| TOKEN_EXPIRE | "90" | Token Expiry Time |
|
||||
| FRIEND_VERIFY | "false" | Friend Verification Enable |
|
||||
| IOS_PUSH_SOUND | "xxx" | iOS |
|
||||
| CALLBACK_ENABLE | "false" | Enable callback |
|
||||
| CALLBACK_TIMEOUT | "5" | Maximum timeout for callback call |
|
||||
| CALLBACK_FAILED_CONTINUE| "true" | fails to continue to the next step |
|
||||
### 2.20. <a name='PrometheusConfiguration-1'></a>Prometheus Configuration
|
||||
|
||||
This section involves configuring Prometheus, including enabling/disabling it and setting up ports for various services.
|
||||
|
||||
#### 2.20.1. <a name='GeneralConfiguration'></a>General Configuration
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| ------------------- | ------------- | ----------------------------- |
|
||||
| `PROMETHEUS_ENABLE` | "false" | Whether to enable Prometheus. |
|
||||
|
||||
#### 2.20.2. <a name='Service-SpecificPrometheusPorts'></a>Service-Specific Prometheus Ports
|
||||
|
||||
| Service | Parameter | Default Port Value | Description |
|
||||
| ------------------------ | ------------------------ | ---------------------------- | -------------------------------------------------- |
|
||||
| User Service | `USER_PROM_PORT` | '20110' | Prometheus port for the User service. |
|
||||
| Friend Service | `FRIEND_PROM_PORT` | '20120' | Prometheus port for the Friend service. |
|
||||
| Message Service | `MESSAGE_PROM_PORT` | '20130' | Prometheus port for the Message service. |
|
||||
| Message Gateway | `MSG_GATEWAY_PROM_PORT` | '20140' | Prometheus port for the Message Gateway. |
|
||||
| Group Service | `GROUP_PROM_PORT` | '20150' | Prometheus port for the Group service. |
|
||||
| Auth Service | `AUTH_PROM_PORT` | '20160' | Prometheus port for the Auth service. |
|
||||
| Push Service | `PUSH_PROM_PORT` | '20170' | Prometheus port for the Push service. |
|
||||
| Conversation Service | `CONVERSATION_PROM_PORT` | '20230' | Prometheus port for the Conversation service. |
|
||||
| RTC Service | `RTC_PROM_PORT` | '21300' | Prometheus port for the RTC service. |
|
||||
| Third Service | `THIRD_PROM_PORT` | '21301' | Prometheus port for the Third service. |
|
||||
| Message Transfer Service | `MSG_TRANSFER_PROM_PORT` | '21400, 21401, 21402, 21403' | Prometheus ports for the Message Transfer service. |
|
||||
|
||||
|
||||
### 2.21. <a name='QiniuCloudKODOConfiguration'></a>Qiniu Cloud Kodo Configuration
|
||||
|
||||
This section involves setting up Qiniu Cloud Kodo, including its endpoint, bucket name, and credentials.
|
||||
|
||||
| Parameter | Example Value | Description |
|
||||
| --------------------- | ------------------------------------------------------------ | ---------------------------------------- |
|
||||
| KODO_ENDPOINT | "[http://s3.cn-east-1.qiniucs.com](http://s3.cn-east-1.qiniucs.com)" | Endpoint URL for Qiniu Cloud Kodo. |
|
||||
| KODO_BUCKET | "demo-9999999" | Bucket name for Qiniu Cloud Kodo. |
|
||||
| KODO_BUCKET_URL | "[http://your.domain.com](http://your.domain.com)" | Bucket URL for Qiniu Cloud Kodo. |
|
||||
| KODO_ACCESS_KEY_ID | [User Defined] | Access key ID for Qiniu Cloud Kodo. |
|
||||
| KODO_ACCESS_KEY_SECRET | [User Defined] | Access key secret for Qiniu Cloud Kodo. |
|
||||
| KODO_SESSION_TOKEN | [User Defined] | Session token for Qiniu Cloud Kodo. |
|
||||
| KODO_PUBLIC_READ | "false" | Public read access. |
|
||||
22
docs/contrib/error-code.md
Normal file
22
docs/contrib/error-code.md
Normal file
@@ -0,0 +1,22 @@
|
||||
## Error Code Standards
|
||||
|
||||
Error codes are one of the important means for users to locate and solve problems. When an application encounters an exception, users can quickly locate and resolve the problem based on the error code and the description and solution of the error code in the documentation.
|
||||
|
||||
### Error Code Naming Standards
|
||||
|
||||
- Follow CamelCase notation;
|
||||
- Error codes are divided into two levels. For example, `InvalidParameter.BindError`, separated by a `.`. The first-level error code is platform-level, and the second-level error code is resource-level, which can be customized according to the scenario;
|
||||
- The second-level error code can only use English letters or numbers ([a-zA-Z0-9]), and should use standard English word spelling, standard abbreviations, RFC term abbreviations, etc.;
|
||||
- The error code should avoid multiple definitions of the same semantics, for example: `InvalidParameter.ErrorBind`, `InvalidParameter.BindError`.
|
||||
|
||||
### First-Level Common Error Codes
|
||||
|
||||
| Error Code | Error Description | Error Type |
|
||||
| ---------------- | ------------------------------------------------------------ | ---------- |
|
||||
| InternalError | Internal error | 1 |
|
||||
| InvalidParameter | Parameter error (including errors in parameter type, format, value, etc.) | 0 |
|
||||
| AuthFailure | Authentication / Authorization error | 0 |
|
||||
| ResourceNotFound | Resource does not exist | 0 |
|
||||
| FailedOperation | Operation failed | 2 |
|
||||
|
||||
> Error Type: 0 represents the client, 1 represents the server, 2 represents both the client / server.
|
||||
102
docs/contrib/git-workflow.md
Normal file
102
docs/contrib/git-workflow.md
Normal file
@@ -0,0 +1,102 @@
|
||||
# Git workflows
|
||||
|
||||
This document is an overview of OpenIM git workflow. It includes conventions, tips, and how to maintain good repository hygiene.
|
||||
|
||||
- [Git workflows](#git-workflows)
|
||||
- [Branching model](#branching-model)
|
||||
- [Branch naming conventions](#branch-naming-conventions)
|
||||
- [Backport policy](#backport-policy)
|
||||
- [Git operations](#git-operations)
|
||||
- [Setting up](#setting-up)
|
||||
- [Branching out](#branching-out)
|
||||
- [Keeping local branches in sync](#keeping-local-branches-in-sync)
|
||||
- [Pushing changes](#pushing-changes)
|
||||
|
||||
## Branching model
|
||||
|
||||
OpenIM project uses the [GitHub flow](https://docs.github.com/en/get-started/quickstart/github-flow) as its branching model, where most of the changes come from repositories forks instead of branches within the same one.
|
||||
|
||||
### Branch naming conventions
|
||||
|
||||
Every forked repository works independently, meaning that any contributor can create branches with the name they see fit. However, it is worth noting that OpenIM mirrors [OpenIM version skew policy](https://github.com/openimsdk/open-im-server-deploy/releases) by maintaining release branches for the most recent three minor releases. The only exception is that the main branch mirrors the latest OpenIM release (3.10) instead of using a `release-` prefixed one.
|
||||
|
||||
```text
|
||||
main -------------------------------------------. (OpenIM 3.10)
|
||||
release-3.0.0 \---------------|---------------. (OpenIM 3.00)
|
||||
release-2.4.0 \---------------. (OpenIM 2.40)
|
||||
```
|
||||
|
||||
|
||||
### Backport policy
|
||||
|
||||
All new work happens on the main branch, which means that for most cases, one should branch out from there and create the pull request against it. If the change involves adding a feature or patching OpenIM, the maintainers will backport it into the supported release branches.
|
||||
|
||||
## Git operations
|
||||
|
||||
There are everyday tasks related to git that every contributor needs to perform, and this section elaborates on them.
|
||||
|
||||
### Setting up
|
||||
|
||||
Creating a OpenIM fork, cloning it, and setting its upstream remote can be summarized on:
|
||||
|
||||
1. Visit <https://github.com/openimsdk/open-im-server-deploy>
|
||||
2. Click the `Fork` button (top right) to establish a cloud-based fork
|
||||
3. Clone fork to local storage
|
||||
4. Add to your fork OpenIM remote as upstream
|
||||
|
||||
Once cloned, in code it would look this way:
|
||||
|
||||
```sh
|
||||
## Clone fork to local storage
|
||||
export user="your github profile name"
|
||||
git clone https://github.com/$user/OpenIM.git
|
||||
# or: git clone git@github.com:$user/OpenIM.git
|
||||
|
||||
## Add OpenIM as upstream to your fork
|
||||
cd OpenIM
|
||||
git remote add upstream https://github.com/openimsdk/open-im-server-deploy.git
|
||||
# or: git remote add upstream git@github.com:openimsdk/open-im-server-deploy.git
|
||||
|
||||
## Ensure to never push to upstream directly
|
||||
git remote set-url --push upstream no_push
|
||||
|
||||
## Confirm that your remotes make sense:
|
||||
git remote -v
|
||||
```
|
||||
|
||||
### Branching out
|
||||
|
||||
Every time one wants to work on a new OpenIM feature, we do:
|
||||
|
||||
1. Get local main branch up to date
|
||||
2. Create a new branch from the main one (i.e.: myfeature branch )
|
||||
|
||||
In code it would look this way:
|
||||
|
||||
```sh
|
||||
## Get local main up to date
|
||||
# Assuming the OpenIM clone is the current working directory
|
||||
git fetch upstream
|
||||
git checkout main
|
||||
git rebase upstream/main
|
||||
|
||||
## Create a new branch from main
|
||||
git checkout -b myfeature
|
||||
```
|
||||
|
||||
### Keeping local branches in sync
|
||||
|
||||
Either when branching out from main or a release one, keep in mind it is worth checking if any change has been pushed upstream by doing:
|
||||
|
||||
```sh
|
||||
git fetch upstream
|
||||
git rebase upstream/main
|
||||
```
|
||||
|
||||
It is suggested to `fetch` then `rebase` instead of `pull` since the latter does a merge, which leaves merge commits. For this, one can consider changing the local repository configuration by doing `git config branch.autoSetupRebase always` to change the behavior of `git pull`, or another non-merge option such as `git pull --rebase`.
|
||||
|
||||
### Pushing changes
|
||||
|
||||
For commit messages and signatures please refer to the [CONTRIBUTING.md](../../CONTRIBUTING.md) document.
|
||||
|
||||
Nobody should push directly to upstream, even if one has such contributor access; instead, prefer [Github's pull request](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/about-pull-requests) mechanism to contribute back into OpenIM. For expectations and guidelines about pull requests, consult the [CONTRIBUTING.md](../../CONTRIBUTING.md) document.
|
||||
176
docs/contrib/gitcherry-pick.md
Normal file
176
docs/contrib/gitcherry-pick.md
Normal file
@@ -0,0 +1,176 @@
|
||||
# Git Cherry-Pick Guide
|
||||
|
||||
- Git Cherry-Pick Guide
|
||||
- [Introduction](#introduction)
|
||||
- [What is git cherry-pick?](#what-is-git-cherry-pick)
|
||||
- [Using git cherry-pick](#using-git-cherry-pick)
|
||||
- [Applying Multiple Commits](#applying-multiple-commits)
|
||||
- [Configurations](#configurations)
|
||||
- [Handling Conflicts](#handling-conflicts)
|
||||
- [Applying Commits from Another Repository](#applying-commits-from-another-repository)
|
||||
|
||||
## Introduction
|
||||
|
||||
Author: @cubxxw
|
||||
|
||||
As OpenIM has progressively embarked on a standardized path, I've had the honor of initiating a significant project, `git cherry-pick`. While some may see it as merely a naming convention in the Go language, it represents more. It's a thoughtful design within the OpenIM project, my very first conscious design, and a first in laying out an extensive collaboration process and copyright management with goals of establishing a top-tier community standard.
|
||||
|
||||
## What is git cherry-pick?
|
||||
|
||||
In multi-branch repositories, transferring commits from one branch to another is common. You can either merge all changes from one branch (using `git merge`) or selectively apply certain commits. This selective application of commits is where `git cherry-pick` comes into play.
|
||||
|
||||
Our collaboration strategy with GitHub necessitates maintenance of multiple `release-v*` branches alongside the `main` branch. To manage this, we mainly develop on the `main` branch and selectively merge into `release-v*` branches. This ensures the `main` branch stays current while the `release-v*` branches remain stable.
|
||||
|
||||
Ensuring this strategy's success extends beyond just documentation; it hinges on well-engineered solutions and automation tools, like Makefile, powerful CI/CD processes, and even Prow.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
- [Contributor License Agreement](https://github.com/openim-sigs/cla) is considered implicit for all code within cherry pick pull requests, **unless there is a large conflict**.
|
||||
- A pull request merged against the `main` branch.
|
||||
- The release branch exists (example: [`release-1.18`](https://github.com/openimsdk/open-im-server-deploy/tree/release-v3.1))
|
||||
- The normal git and GitHub configured shell environment for pushing to your openim-server `origin` fork on GitHub and making a pull request against a configured remote `upstream` that tracks `https://github.com/openimsdk/open-im-server-deploy.git`, including `GITHUB_USER`.
|
||||
- Have GitHub CLI (`gh`) installed following [installation instructions](https://github.com/cli/cli#installation).
|
||||
- A github personal access token which has permissions "repo" and "read:org". Permissions are required for [gh auth login](https://cli.github.com/manual/gh_auth_login) and not used for anything unrelated to cherry-pick creation process (creating a branch and initiating PR).
|
||||
|
||||
## What Kind of PRs are Good for Cherry Picks
|
||||
|
||||
Compared to the normal main branch's merge volume across time, the release branches see one or two orders of magnitude less PRs. This is because there is an order or two of magnitude higher scrutiny. Again, the emphasis is on critical bug fixes, e.g.,
|
||||
|
||||
- Loss of data
|
||||
- Memory corruption
|
||||
- Panic, crash, hang
|
||||
- Security
|
||||
|
||||
A bugfix for a functional issue (not a data loss or security issue) that only affects an alpha feature does not qualify as a critical bug fix.
|
||||
|
||||
If you are proposing a cherry pick and it is not a clear and obvious critical bug fix, please reconsider. If upon reflection you wish to continue, bolster your case by supplementing your PR with e.g.,
|
||||
|
||||
- A GitHub issue detailing the problem
|
||||
- Scope of the change
|
||||
- Risks of adding a change
|
||||
- Risks of associated regression
|
||||
- Testing performed, test cases added
|
||||
- Key stakeholder SIG reviewers/approvers attesting to their confidence in the change being a required backport
|
||||
|
||||
If the change is in cloud provider-specific platform code (which is in the process of being moved out of core openim-server), describe the customer impact, how the issue escaped initial testing, remediation taken to prevent similar future escapes, and why the change cannot be carried in your downstream fork of the openim-server project branches.
|
||||
|
||||
It is critical that our full community is actively engaged on enhancements in the project. If a released feature was not enabled on a particular provider's platform, this is a community miss that needs to be resolved in the `main` branch for subsequent releases. Such enabling will not be backported to the patch release branches.
|
||||
|
||||
## Initiate a Cherry Pick
|
||||
|
||||
### Before you begin
|
||||
|
||||
- Plan to initiate a cherry-pick against *every* supported release branch. If you decide to skip some release branch, explain your decision in a comment to the PR being cherry-picked.
|
||||
- Initiate cherry-picks in order, from newest to oldest supported release branches. For example, if 3.1 is the newest supported release branch, then, before cherry-picking to 2.25, make sure the cherry-pick PR already exists for in 2.26 and 3.1. This helps to prevent regressions as a result of an upgrade to the next release.
|
||||
|
||||
### Steps
|
||||
|
||||
- Run the [cherry pick script](https://github.com/openimsdk/open-im-server-deploy/tree/main/scripts/cherry-pick.sh)
|
||||
|
||||
This example applies a main branch PR #98765 to the remote branch `upstream/release-v3.1`:
|
||||
|
||||
```
|
||||
scripts/cherry-pick.sh upstream/release-v3.1 98765
|
||||
```
|
||||
|
||||
- Be aware the cherry pick script assumes you have a git remote called `upstream` that points at the openim-server github org.
|
||||
|
||||
Please see our [recommended Git workflow](https://github.com/openimsdk/open-im-server-deploy/blob/main/docs/contrib/github-workflow.md#workflow).
|
||||
|
||||
- You will need to run the cherry pick script separately for each patch release you want to cherry pick to. Cherry picks should be applied to all [active](https://github.com/openimsdk/open-im-server-deploy/releases) release branches where the fix is applicable.
|
||||
|
||||
- If `GITHUB_TOKEN` is not set you will be asked for your github password: provide the github [personal access token](https://github.com/settings/tokens) rather than your actual github password. If you can securely set the environment variable `GITHUB_TOKEN` to your personal access token then you can avoid an interactive prompt. Refer [mislav/hub#2655 (comment)](https://github.com/mislav/hub/issues/2655#issuecomment-735836048)
|
||||
|
||||
- Your cherry pick PR will immediately get the `do-not-merge/cherry-pick-not-approved` label.
|
||||
|
||||
|
||||
## Cherry Pick Review
|
||||
|
||||
As with any other PR, code OWNERS review (`/lgtm`) and approve (`/approve`) on cherry pick PRs as they deem appropriate.
|
||||
|
||||
The same release note requirements apply as normal pull requests, except the release note stanza will auto-populate from the main branch pull request from which the cherry pick originated.
|
||||
|
||||
|
||||
## Using git cherry-pick
|
||||
|
||||
`git cherry-pick` applies specified commits from one branch to another.
|
||||
|
||||
```bash
|
||||
$ git cherry-pick <commitHash>
|
||||
```
|
||||
|
||||
As an example, consider a repository with `main` and `release-v3.1` branches. To apply commit `f` from the `release-v3.1` branch to the `main` branch:
|
||||
|
||||
```
|
||||
# Switch to main branch
|
||||
$ git checkout main
|
||||
|
||||
# Perform cherry-pick
|
||||
$ git cherry-pick f
|
||||
```
|
||||
|
||||
You can also use a branch name instead of a commit hash to cherry-pick the latest commit from that branch.
|
||||
|
||||
```bash
|
||||
$ git cherry-pick release-v3.1
|
||||
```
|
||||
|
||||
## Applying Multiple Commits
|
||||
|
||||
To apply multiple commits simultaneously:
|
||||
|
||||
```bash
|
||||
$ git cherry-pick <HashA> <HashB>
|
||||
```
|
||||
|
||||
To apply a range of consecutive commits:
|
||||
|
||||
```bash
|
||||
$ git cherry-pick <HashA>..<HashB>
|
||||
```
|
||||
|
||||
## Configurations
|
||||
|
||||
Here are some commonly used configurations for `git cherry-pick`:
|
||||
|
||||
- **`-e`, `--edit`**: Open an external editor to modify the commit message.
|
||||
- **`-n`, `--no-commit`**: Update the working directory and staging area without creating a new commit.
|
||||
- **`-x`**: Append a reference in the commit message for tracking the source of the cherry-picked commit.
|
||||
- **`-s`, `--signoff`**: Add a sign-off message at the end of the commit indicating who performed the cherry-pick.
|
||||
- **`-m parent-number`, `--mainline parent-number`**: When the original commit is a merge of two branches, specify which parent branch's changes should be used.
|
||||
|
||||
## Handling Conflicts
|
||||
|
||||
If conflicts arise during the cherry-pick:
|
||||
|
||||
- **`--continue`**: After resolving conflicts, stage the changes with `git add .` and then continue the cherry-pick process.
|
||||
- **`--abort`**: Abandon the cherry-pick and revert to the previous state.
|
||||
- **`--quit`**: Exit the cherry-pick without reverting to the previous state.
|
||||
|
||||
## Applying Commits from Another Repository
|
||||
|
||||
You can also cherry-pick commits from another repository:
|
||||
|
||||
1. Add the external repository as a remote:
|
||||
|
||||
```
|
||||
$ git remote add target git://gitUrl
|
||||
```
|
||||
|
||||
2. Fetch the commits from the remote:
|
||||
|
||||
```
|
||||
$ git fetch target
|
||||
```
|
||||
|
||||
3. Identify the commit hash you wish to cherry-pick:
|
||||
|
||||
```
|
||||
$ git log target/main
|
||||
```
|
||||
|
||||
4. Perform the cherry-pick:
|
||||
|
||||
```
|
||||
$ git cherry-pick <commitHash>
|
||||
```
|
||||
283
docs/contrib/github-workflow.md
Normal file
283
docs/contrib/github-workflow.md
Normal file
@@ -0,0 +1,283 @@
|
||||
---
|
||||
title: "GitHub Workflow"
|
||||
weight: 6
|
||||
description: |
|
||||
This document is an overview of the GitHub workflow used by the
|
||||
open-im-server-deploy project. It includes tips and suggestions on keeping your
|
||||
local environment in sync with upstream and how to maintain good
|
||||
commit hygiene.
|
||||
---
|
||||
|
||||
|
||||
## 1. Fork in the cloud
|
||||
|
||||
1. Visit https://github.com/openimsdk/open-im-server-deploy
|
||||
2. Click `Fork` button (top right) to establish a cloud-based fork.
|
||||
|
||||
## 2. Clone fork to local storage
|
||||
|
||||
Per Go's [workspace instructions][go-workspace], place open-im-server-deploy' code on your
|
||||
`GOPATH` using the following cloning procedure.
|
||||
|
||||
[go-workspace]: https://golang.org/doc/code.html#Workspaces
|
||||
|
||||
In your shell, define a local working directory as `working_dir`. If your `GOPATH` has multiple paths, pick
|
||||
just one and use it instead of `$GOPATH`. You must follow exactly this pattern,
|
||||
neither `$GOPATH/src/github.com/${your github profile name}/`
|
||||
nor any other pattern will work.
|
||||
|
||||
```sh
|
||||
export working_dir="$(go env GOPATH)/src/github.com/openimsdk"
|
||||
```
|
||||
|
||||
If you already do Go development on github, the `github.com/openimsdk` directory
|
||||
will be a sibling to your existing `github.com` directory.
|
||||
|
||||
Set `user` to match your github profile name:
|
||||
|
||||
```sh
|
||||
export user=<your github profile name>
|
||||
```
|
||||
|
||||
Both `$working_dir` and `$user` are mentioned in the figure above.
|
||||
|
||||
Create your clone:
|
||||
|
||||
```sh
|
||||
mkdir -p $working_dir
|
||||
cd $working_dir
|
||||
git clone https://github.com/$user/open-im-server-deploy.git
|
||||
# or: git clone git@github.com:$user/open-im-server-deploy.git
|
||||
|
||||
cd $working_dir/open-im-server-deploy
|
||||
git remote add upstream https://github.com/openimsdk/open-im-server-deploy.git
|
||||
# or: git remote add upstream git@github.com:openimsdk/open-im-server-deploy.git
|
||||
|
||||
# Never push to upstream master
|
||||
git remote set-url --push upstream no_push
|
||||
|
||||
# Confirm that your remotes make sense:
|
||||
git remote -v
|
||||
```
|
||||
|
||||
## 3. Create a Working Branch
|
||||
|
||||
Get your local master up to date. Note that depending on which repository you are working from,
|
||||
the default branch may be called "main" instead of "master".
|
||||
|
||||
```sh
|
||||
cd $working_dir/open-im-server-deploy
|
||||
git fetch upstream
|
||||
git checkout master
|
||||
git rebase upstream/master
|
||||
```
|
||||
|
||||
Create your new branch.
|
||||
|
||||
```sh
|
||||
git checkout -b myfeature
|
||||
```
|
||||
|
||||
You may now edit files on the `myfeature` branch.
|
||||
|
||||
### Building open-im-server-deploy
|
||||
|
||||
This workflow is process-specific. For quick-start build instructions for [openimsdk/open-im-server-deploy](https://github.com/openimsdk/open-im-server-deploy/blob/main/docs/contrib/util-makefile.md)
|
||||
|
||||
## 4. Keep your branch in sync
|
||||
|
||||
You will need to periodically fetch changes from the `upstream`
|
||||
repository to keep your working branch in sync. Note that depending on which repository you are working from,
|
||||
the default branch may be called 'main' instead of 'master'.
|
||||
|
||||
Make sure your local repository is on your working branch and run the
|
||||
following commands to keep it in sync:
|
||||
|
||||
```sh
|
||||
git fetch upstream
|
||||
git rebase upstream/master
|
||||
```
|
||||
|
||||
Please don't use `git pull` instead of the above `fetch` and
|
||||
`rebase`. Since `git pull` executes a merge, it creates merge commits. These make the commit history messy
|
||||
and violate the principle that commits ought to be individually understandable
|
||||
and useful (see below).
|
||||
|
||||
You might also consider changing your `.git/config` file via
|
||||
`git config branch.autoSetupRebase always` to change the behavior of `git pull`, or another non-merge option such as `git pull --rebase`.
|
||||
|
||||
## 5. Commit Your Changes
|
||||
|
||||
You will probably want to regularly commit your changes. It is likely that you will go back and edit,
|
||||
build, and test multiple times. After a few cycles of this, you might
|
||||
[amend your previous commit](https://www.w3schools.com/git/git_amend.asp).
|
||||
|
||||
```sh
|
||||
git commit
|
||||
```
|
||||
|
||||
## 6. Push to GitHub
|
||||
|
||||
When your changes are ready for review, push your working branch to
|
||||
your fork on GitHub.
|
||||
|
||||
```sh
|
||||
git push -f <your_remote_name> myfeature
|
||||
```
|
||||
|
||||
## 7. Create a Pull Request
|
||||
|
||||
1. Visit your fork at `https://github.com/<user>/open-im-server-deploy`
|
||||
2. Click the **Compare & Pull Request** button next to your `myfeature` branch.
|
||||
3. Check out the pull request process for more details and
|
||||
advice.
|
||||
|
||||
_If you have upstream write access_, please refrain from using the GitHub UI for
|
||||
creating PRs, because GitHub will create the PR branch inside the main
|
||||
repository rather than inside your fork.
|
||||
|
||||
### Get a code review
|
||||
|
||||
Once your pull request has been opened it will be assigned to one or more
|
||||
reviewers. Those reviewers will do a thorough code review, looking for
|
||||
correctness, bugs, opportunities for improvement, documentation and comments,
|
||||
and style.
|
||||
|
||||
Commit changes made in response to review comments to the same branch on your
|
||||
fork.
|
||||
|
||||
Very small PRs are easy to review. Very large PRs are very difficult to review.
|
||||
|
||||
### Squash commits
|
||||
|
||||
After a review, prepare your PR for merging by squashing your commits.
|
||||
|
||||
All commits left on your branch after a review should represent meaningful milestones or units of work. Use commits to add clarity to the development and review process.
|
||||
|
||||
Before merging a PR, squash the following kinds of commits:
|
||||
|
||||
- Fixes/review feedback
|
||||
- Typos
|
||||
- Merges and rebases
|
||||
- Work in progress
|
||||
|
||||
Aim to have every commit in a PR compile and pass tests independently if you can, but it's not a requirement. In particular, `merge` commits must be removed, as they will not pass tests.
|
||||
|
||||
To squash your commits, perform an [interactive rebase](https://git-scm.com/book/en/v2/Git-Tools-Rewriting-History):
|
||||
|
||||
1. Check your git branch:
|
||||
|
||||
```
|
||||
git status
|
||||
```
|
||||
|
||||
The output should be similar to this:
|
||||
|
||||
```
|
||||
On branch your-contribution
|
||||
Your branch is up to date with 'origin/your-contribution'.
|
||||
```
|
||||
|
||||
2. Start an interactive rebase using a specific commit hash, or count backwards from your last commit using `HEAD~<n>`, where `<n>` represents the number of commits to include in the rebase.
|
||||
|
||||
```
|
||||
git rebase -i HEAD~3
|
||||
```
|
||||
|
||||
The output should be similar to this:
|
||||
|
||||
```
|
||||
pick 2ebe926 Original commit
|
||||
pick 31f33e9 Address feedback
|
||||
pick b0315fe Second unit of work
|
||||
|
||||
# Rebase 7c34fc9..b0315ff onto 7c34fc9 (3 commands)
|
||||
#
|
||||
# Commands:
|
||||
# p, pick <commit> = use commit
|
||||
# r, reword <commit> = use commit, but edit the commit message
|
||||
# e, edit <commit> = use commit, but stop for amending
|
||||
# s, squash <commit> = use commit, but meld into previous commit
|
||||
# f, fixup <commit> = like "squash", but discard this commit's log message
|
||||
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
3. Use a command line text editor to change the word `pick` to `squash` for the commits you want to squash, then save your changes and continue the rebase:
|
||||
|
||||
```
|
||||
pick 2ebe926 Original commit
|
||||
squash 31f33e9 Address feedback
|
||||
pick b0315fe Second unit of work
|
||||
|
||||
...
|
||||
|
||||
```
|
||||
|
||||
The output after saving changes should look similar to this:
|
||||
|
||||
```
|
||||
[detached HEAD 61fdded] Second unit of work
|
||||
Date: Thu Mar 5 19:01:32 2020 +0100
|
||||
2 files changed, 15 insertions(+), 1 deletion(-)
|
||||
|
||||
...
|
||||
|
||||
Successfully rebased and updated refs/heads/master.
|
||||
```
|
||||
4. Force push your changes to your remote branch:
|
||||
|
||||
```
|
||||
git push --force
|
||||
```
|
||||
|
||||
For mass automated fixups such as automated doc formatting, use one or more
|
||||
commits for the changes to tooling and a final commit to apply the fixup en
|
||||
masse. This makes reviews easier.
|
||||
|
||||
An alternative to this manual squashing process is to use the Prow and Tide based automation that is configured in GitHub: adding a comment to your PR with `/label tide/merge-method-squash` will trigger the automation so that GitHub squash your commits onto the target branch once the PR is approved. Using this approach simplifies things for those less familiar with Git, but there are situations in where it's better to squash locally; reviewers will have this in mind and can ask for manual squashing to be done.
|
||||
|
||||
By squashing locally, you control the commit message(s) for your work, and can separate a large PR into logically separate changes.
|
||||
For example: you have a pull request that is code complete and has 24 commits. You rebase this against the same merge base, simplifying the change to two commits. Each of those two commits represents a single logical change and each commit message summarizes what changes. Reviewers see that the set of changes are now understandable, and approve your PR.
|
||||
|
||||
## Merging a commit
|
||||
|
||||
Once you've received review and approval, your commits are squashed, your PR is ready for merging.
|
||||
|
||||
Merging happens automatically after both a Reviewer and Approver have approved the PR. If you haven't squashed your commits, they may ask you to do so before approving a PR.
|
||||
|
||||
## Reverting a commit
|
||||
|
||||
In case you wish to revert a commit, use the following instructions.
|
||||
|
||||
_If you have upstream write access_, please refrain from using the
|
||||
`Revert` button in the GitHub UI for creating the PR, because GitHub
|
||||
will create the PR branch inside the main repository rather than inside your fork.
|
||||
|
||||
- Create a branch and sync it with upstream. Note that depending on which repository you are working from, the default branch may be called 'main' instead of 'master'.
|
||||
```sh
|
||||
# create a branch
|
||||
git checkout -b myrevert
|
||||
|
||||
# sync the branch with upstream
|
||||
git fetch upstream
|
||||
git rebase upstream/master
|
||||
```
|
||||
- If the commit you wish to revert is a *merge commit*, use this command:
|
||||
```sh
|
||||
# SHA is the hash of the merge commit you wish to revert
|
||||
git revert -m 1 <SHA>
|
||||
```
|
||||
If it is a *single commit*, use this command:
|
||||
```sh
|
||||
# SHA is the hash of the single commit you wish to revert
|
||||
git revert <SHA>
|
||||
```
|
||||
|
||||
- This will create a new commit reverting the changes. Push this new commit to your remote.
|
||||
```sh
|
||||
git push <your_remote_name> myrevert
|
||||
```
|
||||
|
||||
- Finally, [create a Pull Request](#7-create-a-pull-request) using this branch.
|
||||
1478
docs/contrib/go-code.md
Normal file
1478
docs/contrib/go-code.md
Normal file
File diff suppressed because it is too large
Load Diff
1554
docs/contrib/go-code1.md
Normal file
1554
docs/contrib/go-code1.md
Normal file
File diff suppressed because it is too large
Load Diff
50
docs/contrib/go-doc.md
Normal file
50
docs/contrib/go-doc.md
Normal file
@@ -0,0 +1,50 @@
|
||||
# Go Language Documentation for OpenIM
|
||||
|
||||
In the realm of software development, especially within Go language projects, documentation plays a crucial role in ensuring code maintainability and ease of use. Properly written and accurate documentation is not only essential for understanding and utilizing software effectively but also needs to be easy to write and maintain. This principle is at the heart of OpenIM's approach to supporting commands and generating documentation.
|
||||
|
||||
## Supported Commands in OpenIM
|
||||
|
||||
OpenIM leverages Go language's documentation standards to facilitate clear and maintainable code documentation. Below are some of the key commands used in OpenIM for documentation purposes:
|
||||
|
||||
### `go doc` Command
|
||||
|
||||
The `go doc` command is used to print documentation for Go language entities such as variables, constants, functions, structures, and interfaces. This command allows specifying the identifier of the program entity to tailor the output. Examples of `go doc` command usage include:
|
||||
|
||||
- `go doc sync.WaitGroup.Add` prints the documentation for a specific method of a type in a package.
|
||||
- `go doc -u -all sync.WaitGroup` displays all program entities, including unexported ones, for a specified type.
|
||||
- `go doc -u sync` outputs all program entities for a specified package, focusing on exported ones without detailed comments.
|
||||
|
||||
### `godoc` Command
|
||||
|
||||
For environments lacking internet access, the `godoc` command serves to view the Go language standard library and project dependency library documentation in a web format. Notably, post-Go 1.12 versions, `godoc` is not part of the Go compiler suite. It can be installed using:
|
||||
|
||||
```shell
|
||||
go get -u -v golang.org/x/tools/cmd/godoc
|
||||
```
|
||||
|
||||
The `godoc` command, once running, hosts a local web server (by default on port 6060) to facilitate documentation browsing at http://127.0.0.1:6060. It generates documentation based on the GOROOT and GOPATH directories, showcasing both the project's own documentation and that of third-party packages installed via `go get`.
|
||||
|
||||
### Custom Documentation Generation Commands in OpenIM
|
||||
|
||||
OpenIM includes a suite of commands aimed at initializing, generating, and maintaining project documentation and associated files. Some notable commands are:
|
||||
|
||||
- `gen.init`: Initializes the OpenIM server project.
|
||||
- `gen.docgo`: Generates missing `doc.go` files for Go packages, crucial for package-level documentation.
|
||||
- `gen.errcode.doc`: Generates markdown documentation for OpenIM error codes.
|
||||
- `gen.ca`: Generates CA files for all certificates, enhancing security documentation.
|
||||
|
||||
These commands underscore the project's commitment to thorough and accessible documentation, supporting both developers and users alike.
|
||||
|
||||
## Writing Your Own Documentation
|
||||
|
||||
When creating documentation for Go projects, including OpenIM, it's important to follow certain practices:
|
||||
|
||||
1. **Commenting**: Use single-line (`//`) and block (`/* */`) comments to provide detailed documentation within the code. Block comments are especially useful for package documentation, which should immediately precede the package statement without any intervening blank lines.
|
||||
|
||||
2. **Overview Section**: To create an overview section in the documentation, place a block comment directly before the package statement. This section should succinctly describe the package's purpose and functionality.
|
||||
|
||||
3. **Detailed Descriptions**: Comments placed before functions, structures, or variables will be used to generate detailed descriptions in the documentation. Follow the same commenting rules as for the overview section.
|
||||
|
||||
4. **Examples**: Include example functions prefixed with `Example` to demonstrate usage. Output from these examples can be documented at the end of the function, starting with `// Output:` followed by the expected result.
|
||||
|
||||
Through adherence to these documentation practices, OpenIM ensures that its codebase remains accessible, maintainable, and easy to use for developers and users alike.
|
||||
116
docs/contrib/images.md
Normal file
116
docs/contrib/images.md
Normal file
@@ -0,0 +1,116 @@
|
||||
# OpenIM Image Management Strategy and Pulling Guide
|
||||
|
||||
OpenIM is an efficient, stable, and scalable instant messaging framework that provides convenient deployment methods through Docker images. OpenIM manages multiple image sources, hosted respectively on GitHub (ghcr), Alibaba Cloud, and Docker Hub. This document is aimed at detailing the image management strategy of OpenIM and providing the steps for pulling these images.
|
||||
|
||||
|
||||
## Image Management Strategy
|
||||
|
||||
OpenIM's versions correspond to GitHub's tag versions. Each time we release a new version and tag it on GitHub, an automated process is triggered that pushes the new Docker image version to the following three platforms:
|
||||
|
||||
1. **GitHub (ghcr.io):** We use GitHub Container Registry (ghcr.io) to host OpenIM's Docker images. This allows us to better integrate with the GitHub source code repository, providing better version control and continuous integration/deployment (CI/CD) features. You can view all GitHub images [here](https://github.com/orgs/OpenIMSDK/packages).
|
||||
2. **Alibaba Cloud (registry.cn-hangzhou.aliyuncs.com):** For users in Mainland China, we also host OpenIM's Docker images on Alibaba Cloud to provide faster pull speeds. You can view all Alibaba Cloud images on this [page](https://cr.console.aliyun.com/cn-hangzhou/instances/repositories) of Alibaba Cloud Image Service (note that you need to log in to your Alibaba Cloud account first).
|
||||
3. **Docker Hub (docker.io):** Docker Hub is the most commonly used Docker image hosting platform, and we also host OpenIM's images there to facilitate developers worldwide. You can view all Docker Hub images on the [OpenIM's Docker Hub page](https://hub.docker.com/r/openim).
|
||||
|
||||
## Base images design
|
||||
|
||||
+ [https://github.com/openim-sigs/openim-base-image](https://github.com/openim-sigs/openim-base-image)
|
||||
|
||||
## OpenIM Image Design and Usage Guide
|
||||
|
||||
OpenIM offers a comprehensive and flexible system of Docker images, available across multiple repositories. We actively maintain these images across different platforms, namely GitHub's ghcr.io, Alibaba Cloud, and Docker Hub. However, we highly recommend ghcr.io for deployment.
|
||||
|
||||
### Available Versions
|
||||
|
||||
We provide multiple versions of our images to meet different project requirements. Here's a quick overview of what you can expect:
|
||||
|
||||
1. `main`: This image corresponds to the latest version of the main branch in OpenIM. It is updated frequently, making it perfect for users who want to stay at the cutting edge of our features.
|
||||
2. `release-v3.*`: This is the image that corresponds to the latest version of OpenIM's stable release branch. It's ideal for users who prefer a balance between new features and stability.
|
||||
3. `v3.*.*`: These images are specific to each tag in OpenIM. They are preserved in their original state and are never overwritten. These are the go-to images for users who need a specific, unchanging version of OpenIM.
|
||||
4. The image versions adhere to Semantic Versioning 2.0.0 strategy. Taking the `openim-server` image as an example, available at [openim-server container package](https://github.com/openimsdk/open-im-server-deploy/pkgs/container/openim-server): upon tagging with v3.5.0, the CI automatically releases the following tags - `openim-server:3`, `openim-server:3.5`, `openim-server:3.5.0`, `openim-server:v3.5.0`, `openim-server:latest`, and `sha-e0244d9`. It's important to note that only `sha-e0244d9` is absolutely unique, whereas `openim-server:v3.5.0` and `openim-server:3.5.0` maintain a degree of uniqueness.
|
||||
|
||||
### Multi-Architecture Images
|
||||
|
||||
In order to cater to a wider range of needs, some of our images are provided with multiple architectures under `OS / Arch`. These images offer greater compatibility across different operating systems and hardware architectures, ensuring that OpenIM can be deployed virtually anywhere.
|
||||
|
||||
**Example:**
|
||||
|
||||
+ [https://github.com/OpenIMSDK/chat/pkgs/container/openim-chat/113925695?tag=v1.1.0](https://github.com/OpenIMSDK/chat/pkgs/container/openim-chat/113925695?tag=v1.1.0)
|
||||
|
||||
|
||||
## Methods and Steps for Pulling Images
|
||||
|
||||
When pulling OpenIM's Docker images, you can choose the most suitable source based on your geographic location and network conditions. Here are the steps to pull OpenIM images from each source:
|
||||
|
||||
### Select image
|
||||
|
||||
1. Choose the image repository platform you prefer. As previously mentioned, we recommend [OpenIM ghcr.io](https://github.com/orgs/OpenIMSDK/packages).
|
||||
|
||||
2. Choose the image name and image version that suits your needs. Refer to the description above for more details.
|
||||
|
||||
|
||||
### Install image
|
||||
|
||||
1. First, make sure Docker is installed on your machine. If not, you can refer to the [Docker official documentation](https://docs.docker.com/get-docker/) for installation.
|
||||
|
||||
2. Open the terminal and run the following commands to pull the images:
|
||||
|
||||
For OpenIM Server:
|
||||
|
||||
- Pull from GitHub:
|
||||
|
||||
```bash
|
||||
docker pull ghcr.io/openimsdk/openim-server:latest
|
||||
```
|
||||
|
||||
- Pull from Alibaba Cloud:
|
||||
|
||||
```bash
|
||||
docker pull registry.cn-hangzhou.aliyuncs.com/openimsdk/openim-server:latest
|
||||
```
|
||||
|
||||
- Pull from Docker Hub:
|
||||
|
||||
```bash
|
||||
docker pull docker.io/openim/openim-server:latest
|
||||
```
|
||||
|
||||
For OpenIM Chat:
|
||||
|
||||
- Pull from GitHub:
|
||||
|
||||
```bash
|
||||
docker pull ghcr.io/openimsdk/openim-chat:latest
|
||||
```
|
||||
|
||||
- Pull from Alibaba Cloud:
|
||||
|
||||
```bash
|
||||
docker pull registry.cn-hangzhou.aliyuncs.com/openimsdk/openim-chat:latest
|
||||
```
|
||||
|
||||
- Pull from Docker Hub:
|
||||
|
||||
```bash
|
||||
docker pull docker.io/openim/openim-chat:latest
|
||||
```
|
||||
|
||||
3. Run the `docker images` command to confirm that the image has been successfully pulled.
|
||||
|
||||
### Accelerating Deployment for Users in China with Aliyun Mirror or Alternative Image Addresses
|
||||
|
||||
For users in China looking to speed up the deployment process of OpenIM, leveraging a mirror image address is a highly recommended practice. After executing the `make init` command, a `.env` file is generated, which you'll need to edit to configure the image registry source. This configuration is crucial for optimizing download speeds and ensuring a smoother setup process.
|
||||
|
||||
Within the generated `.env` file, you'll find a section dedicated to choosing the image address. It includes options for GitHub (`ghcr.io/openimsdk`), Docker Hub (`openim`), and Ali Cloud (`registry.cn-hangzhou.aliyuncs.com/openimsdk`). To achieve the best performance within China, it is advised to use the Aliyun image address.
|
||||
|
||||
To do this, you need to comment out the current `IMAGE_REGISTRY` setting and uncomment the Aliyun option. Here is how you can adjust it for Aliyun:
|
||||
|
||||
```bash
|
||||
# Choose the image address: GitHub (ghcr.io/openimsdk), Docker Hub (openim),
|
||||
# or Ali Cloud (registry.cn-hangzhou.aliyuncs.com/openimsdk).
|
||||
# Uncomment one of the following three options. Aliyun is recommended for users in China.
|
||||
# IMAGE_REGISTRY="ghcr.io/openimsdk"
|
||||
# IMAGE_REGISTRY="openim"
|
||||
IMAGE_REGISTRY="registry.cn-hangzhou.aliyuncs.com/openimsdk"
|
||||
```
|
||||
|
||||
This change directs the deployment process to fetch the required images from the Aliyun registry, significantly improving download and installation speeds due to the geographical and network advantages within China. If, for any reason, you prefer not to use Aliyun or encounter issues, consider switching to another mirror address listed in the `.env` file by following the same uncommenting process. This flexibility ensures that users can select the most suitable image source for their specific situation, leading to a more efficient deployment of OpenIM.
|
||||
74
docs/contrib/init-config.md
Normal file
74
docs/contrib/init-config.md
Normal file
@@ -0,0 +1,74 @@
|
||||
# Init OpenIM Config
|
||||
|
||||
- [Init OpenIM Config](#init-openim-config)
|
||||
- [Start](#start)
|
||||
- [Define Automated Configuration](#define-automated-configuration)
|
||||
- [Define Configuration Variables](#define-configuration-variables)
|
||||
- [Bash Parsing Features](#bash-parsing-features)
|
||||
- [Reasons and Advantages of the Design](#reasons-and-advantages-of-the-design)
|
||||
|
||||
|
||||
## Start
|
||||
|
||||
With the increasing complexity of software engineering, effective configuration management has become more and more important. Yaml and other configuration files provide the necessary parameters and guidance for systems, but they also impose additional management overhead for developers. This article explores how to automate and optimize configuration management, thereby improving efficiency and reducing the chances of errors.
|
||||
|
||||
First, obtain the OpenIM code through the contributor documentation and initialize it following the steps below.
|
||||
|
||||
## Define Automated Configuration
|
||||
|
||||
We no longer strongly recommend modifying the same configuration file. If you have a new configuration file related to your business, we suggest generating and managing it through automation.
|
||||
|
||||
In the `scripts/init_config.sh` file, we defined some template files. These templates will be automatically generated to the corresponding directories when executing `make init`.
|
||||
|
||||
```
|
||||
# Defines an associative array where the keys are the template files and the values are the corresponding output files.
|
||||
declare -A TEMPLATES=(
|
||||
["${OPENIM_ROOT}/scripts/template/config-tmpl/env.template"]="${OPENIM_OUTPUT_SUBPATH}/bin/.env"
|
||||
["${OPENIM_ROOT}/scripts/template/config-tmpl/config.yaml"]="${OPENIM_OUTPUT_SUBPATH}/bin/config.yaml"
|
||||
)
|
||||
```
|
||||
|
||||
If you have your new mapping files, you can implement them by appending them to the array.
|
||||
|
||||
Lastly, run:
|
||||
|
||||
```
|
||||
./scripts/init_config.sh
|
||||
```
|
||||
|
||||
## Define Configuration Variables
|
||||
|
||||
In the `scripts/install/environment.sh` file, we defined many reusable variables for automation convenience.
|
||||
|
||||
In the provided example, the def function is a core element. This function not only provides a concise way to define variables but also offers default value options for each variable. This way, even if a specific variable is not explicitly set in an environment or scenario, it can still have an expected value.
|
||||
|
||||
```
|
||||
function def() {
|
||||
local var_name="$1"
|
||||
local default_value="$2"
|
||||
eval "readonly $var_name=\${$var_name:-$default_value}"
|
||||
}
|
||||
```
|
||||
|
||||
### Bash Parsing Features
|
||||
|
||||
Since bash is a parsing script language, it executes commands in the order they appear in the script. This characteristic means we can define commonly used or core variables at the beginning of the script and then reuse or modify them later on.
|
||||
|
||||
For instance, we can initially set a universal password and reuse this password in subsequent variable definitions.
|
||||
|
||||
```
|
||||
# Set a consistent password for easy memory
|
||||
def "PASSWORD" "openIM123"
|
||||
|
||||
# Linux system user for openim
|
||||
def "LINUX_USERNAME" "openim"
|
||||
def "LINUX_PASSWORD" "${PASSWORD}"
|
||||
```
|
||||
|
||||
## Reasons and Advantages of the Design
|
||||
|
||||
1. **Simplify Configuration Management**: Through automation scripts, we can avoid manual operations and configurations, thus reducing tedious repetitive tasks.
|
||||
2. **Reduce Errors**: Manually editing yaml or other configuration files can lead to formatting mistakes or typographical errors. Automating with scripts can lower the risk of such errors.
|
||||
3. **Enhanced Readability**: Using the `def` function and other bash scripting techniques, we can establish a clear, easy-to-read, and maintainable configuration system.
|
||||
4. **Improved Reusability**: As demonstrated above, we can reuse variables and functions in different parts of the script, reducing redundant code and increasing overall consistency.
|
||||
5. **Flexible Default Value Mechanism**: By providing default values for variables, we can ensure configurations are complete and consistent across various scenarios, while also offering customization options for advanced users.
|
||||
53
docs/contrib/install-docker.md
Normal file
53
docs/contrib/install-docker.md
Normal file
@@ -0,0 +1,53 @@
|
||||
<!-- vscode-markdown-toc -->
|
||||
|
||||
<!-- vscode-markdown-toc-config
|
||||
numbering=true
|
||||
autoSave=true
|
||||
/vscode-markdown-toc-config -->
|
||||
<!-- /vscode-markdown-toc -->
|
||||
# Install Docker
|
||||
|
||||
|
||||
The installation command is as follows:
|
||||
|
||||
```bash
|
||||
$ curl -fsSL https://get.docker.com | bash -s docker --mirror aliyun
|
||||
``
|
||||
|
||||
## 2.2 Start Docker
|
||||
|
||||
```bash
|
||||
$ systemctl start docker
|
||||
```
|
||||
|
||||
## 2.3 Test Docker
|
||||
|
||||
```bash
|
||||
$ docker run hello-world
|
||||
```
|
||||
|
||||
## 2.4 Configure Docker Acceleration
|
||||
|
||||
```bash
|
||||
$ mkdir -p /etc/docker
|
||||
$ tee /etc/docker/daemon.json <<-'EOF'
|
||||
{
|
||||
"registry-mirrors": ["https://registry.docker-cn.com"]
|
||||
}
|
||||
EOF
|
||||
$ systemctl daemon-reload
|
||||
$ systemctl restart docker
|
||||
```
|
||||
|
||||
## 2.5 Install Docker Compose
|
||||
|
||||
```bash
|
||||
$ sudo curl -L "https://github.com/docker/compose/releases/download/latest/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
|
||||
$ sudo chmod +x /usr/local/bin/docker-compose
|
||||
```
|
||||
|
||||
## 2.6 Test Docker Compose
|
||||
|
||||
```bash
|
||||
$ docker-compose --version
|
||||
```
|
||||
353
docs/contrib/install-openim-linux-system.md
Normal file
353
docs/contrib/install-openim-linux-system.md
Normal file
@@ -0,0 +1,353 @@
|
||||
# OpenIM System: Setup and Usage Guide
|
||||
|
||||
<!-- vscode-markdown-toc -->
|
||||
* 1. [1. Introduction](#Introduction)
|
||||
* 2. [2. Prerequisites (Requires root permissions)](#PrerequisitesRequiresrootpermissions)
|
||||
* 3. [3. Create `openim-api` systemd unit template file](#Createopenim-apisystemdunittemplatefile)
|
||||
* 4. [4. Copy systemd unit template file to systemd config directory (Requires root permissions)](#CopysystemdunittemplatefiletosystemdconfigdirectoryRequiresrootpermissions)
|
||||
* 5. [5. Start systemd service](#Startsystemdservice)
|
||||
|
||||
|
||||
## 0. <a name='Introduction'></a>0. Introduction
|
||||
|
||||
Systemd is the default service management form for the latest Linux distributions, replacing the original init.
|
||||
|
||||
The OpenIM system is a comprehensive suite of services tailored to address a wide variety of messaging needs. This guide will walk you through the steps of setting up the OpenIM system services and provide insights into its usage.
|
||||
|
||||
**Prerequisites:**
|
||||
|
||||
+ A Linux server with necessary privileges.
|
||||
+ Ensure you have `systemctl` installed and running.
|
||||
|
||||
|
||||
## 1. <a name='Deployment'></a>1. Deployment
|
||||
|
||||
1. **Retrieve the Installation Script**:
|
||||
|
||||
Begin by obtaining the OpenIM installation script which will be utilized to deploy the entire OpenIM system.
|
||||
|
||||
2. **Install OpenIM**:
|
||||
|
||||
To install all the components of OpenIM, run:
|
||||
|
||||
```bash
|
||||
./scripts/install/install.sh -i
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```bash
|
||||
./scripts/install/install.sh --install
|
||||
```
|
||||
|
||||
This will initiate the installation process for all OpenIM components.
|
||||
|
||||
3. **Check the Status**:
|
||||
|
||||
Post installation, it is good practice to verify if all the services are running as expected:
|
||||
|
||||
```bash
|
||||
systemctl status openim.target
|
||||
```
|
||||
|
||||
This will list the status of all related services of OpenIM.
|
||||
|
||||
**Maintenance & Management:**
|
||||
|
||||
1. **Checking Individual Service Status**:
|
||||
|
||||
You can monitor the status of individual services with the following command:
|
||||
|
||||
```bash
|
||||
systemctl status <service-name>
|
||||
```
|
||||
|
||||
For instance:
|
||||
|
||||
```bash
|
||||
systemctl status openim-api.service
|
||||
``
|
||||
|
||||
2. **Starting and Stopping Services**:
|
||||
|
||||
If you wish to start or stop any specific service, you can do so with `systemctl start` or `systemctl stop` followed by the service name:
|
||||
|
||||
```bash
|
||||
systemctl start openim-api.service
|
||||
systemctl stop openim-api.service
|
||||
```
|
||||
|
||||
3. **Uninstalling OpenIM**:
|
||||
|
||||
In case you wish to remove the OpenIM components from your server, utilize:
|
||||
|
||||
```bash
|
||||
./scripts/install/install.sh -u
|
||||
```
|
||||
|
||||
or
|
||||
|
||||
```bash
|
||||
./scripts/install/install.sh --uninstall
|
||||
```
|
||||
|
||||
Ensure you take a backup of any important data before executing the uninstall command.
|
||||
|
||||
4. **Logs & Troubleshooting**:
|
||||
|
||||
Logs play a pivotal role in understanding the system's operation and troubleshooting any issues. OpenIM logs can typically be found in the directory specified during installation, usually `${OPENIM_LOG_DIR}`.
|
||||
|
||||
Always refer to the logs when troubleshooting. Look for any error messages or warnings that might give insights into the issue at hand.
|
||||
|
||||
|
||||
**Note:**
|
||||
|
||||
+ `openim-api.service`: Manages the main API gateways for OpenIM communication.
|
||||
+ `openim-crontask.service`: Manages scheduled tasks and jobs.
|
||||
+ `openim-msggateway.service`: Takes care of message gateway operations.
|
||||
+ `openim-msgtransfer.service`: Handles message transfer functionalities.
|
||||
+ `openim-push.service`: Responsible for push notification services.
|
||||
+ `openim-rpc-auth.service`: Manages RPC (Remote Procedure Call) for authentication.
|
||||
+ `openim-rpc-conversation.service`: Manages RPC for conversations.
|
||||
+ `openim-rpc-friend.service`: Handles RPC for friend-related operations.
|
||||
+ `openim-rpc-group.service`: Manages group-related RPC operations.
|
||||
+ `openim-rpc-msg.service`: Takes care of message RPCs.
|
||||
+ `openim-rpc-third.service`: Deals with third-party integrations using RPC.
|
||||
+ `openim-rpc-user.service`: Manages user-related RPC operations.
|
||||
+ `openim.target`: A target that bundles all the above services for collective operations.
|
||||
|
||||
|
||||
**Viewing Logs with `journalctl`:**
|
||||
|
||||
`systemctl` services usually log their output to the systemd journal, which you can access using the `journalctl` command.
|
||||
|
||||
1. **View Logs for a Specific Service**:
|
||||
|
||||
To view the logs for a particular service, you can use:
|
||||
|
||||
```bash
|
||||
journalctl -u <service-name>
|
||||
```
|
||||
|
||||
For example, to see the logs for the `openim-api.service`, you would use:
|
||||
|
||||
```bash
|
||||
journalctl -u openim-api.service
|
||||
```
|
||||
|
||||
2. **Filtering Logs**:
|
||||
|
||||
+ By Time
|
||||
|
||||
: If you wish to see logs since a specific time:
|
||||
|
||||
```bash
|
||||
journalctl -u openim-api.service --since "2023-10-28 12:00:00"
|
||||
```
|
||||
|
||||
+ Most Recent Logs
|
||||
|
||||
: To view the most recent logs, you can combine
|
||||
`tail` functionality with `journalctl`:
|
||||
|
||||
```bash
|
||||
journalctl -u openim-api.service -n 100
|
||||
```
|
||||
|
||||
3. **Continuous Monitoring of Logs**:
|
||||
|
||||
To see new log messages in real-time, you can use the `-f` flag, which mimics the behavior of `tail -f`:
|
||||
|
||||
```bash
|
||||
journalctl -u openim-api.service -f
|
||||
```
|
||||
|
||||
### Continued Maintenance:
|
||||
|
||||
1. **Regularly Check Service Status**:
|
||||
|
||||
It's good practice to routinely verify that all services are active and running. This can be done with:
|
||||
|
||||
```bash
|
||||
systemctl status openim-api.service openim-push.service openim-rpc-group.service openim-crontask.service openim-rpc-auth.service openim-rpc-msg.service openim-msggateway.service openim-rpc-conversation.service openim-rpc-third.service openim-msgtransfer.service openim-rpc-friend.service openim-rpc-user.service
|
||||
```
|
||||
|
||||
2. **Update Services**:
|
||||
|
||||
Periodically, there might be updates or patches to the OpenIM system or its components. Make sure you keep the system updated. After updating any service, always reload the daemon and restart the service:
|
||||
|
||||
```bash
|
||||
systemctl daemon-reload
|
||||
systemctl restart openim-api.service
|
||||
```
|
||||
|
||||
3. **Backup Important Data**:
|
||||
|
||||
Regularly backup any configuration files, user data, and other essential data. This ensures that you can restore the system to a working state in case of failures.
|
||||
|
||||
### Important `systemctl` and Logging Commands to Learn:
|
||||
|
||||
1. **Start/Stop/Restart Services**:
|
||||
|
||||
```bash
|
||||
systemctl start <service-name>
|
||||
systemctl stop <service-name>
|
||||
systemctl restart <service-name>
|
||||
```
|
||||
|
||||
2. **Enable/Disable Services**:
|
||||
|
||||
If you want a service to start automatically at boot:
|
||||
|
||||
```bash
|
||||
systemctl enable <service-name>
|
||||
```
|
||||
|
||||
To prevent it from starting at boot:
|
||||
|
||||
```bash
|
||||
systemctl disable <service-name>
|
||||
```
|
||||
|
||||
3. **Check Failed Services**:
|
||||
|
||||
To quickly check if any service has failed:
|
||||
|
||||
```bash
|
||||
systemctl --failed
|
||||
```
|
||||
|
||||
4. **Log Rotation**:
|
||||
|
||||
`journalctl` logs can grow large. To clear all archived journal entries, use:
|
||||
|
||||
```bash
|
||||
journalctl --vacuum-time=1d
|
||||
```
|
||||
|
||||
|
||||
**Advanced requirements:**
|
||||
|
||||
- Convenient service runtime log recording for problem analysis
|
||||
- Service management logs
|
||||
- Option to restart upon abnormal exit
|
||||
|
||||
The daemon does not meet these advanced requirements.
|
||||
|
||||
`nohup` only logs the service's runtime outputs and errors.
|
||||
|
||||
Only systemd can fulfill all of the above requirements.
|
||||
|
||||
> The default logs are enhanced with timestamps, usernames, service names, PIDs, etc., making them user-friendly. You can view logs of abnormal service exits. Advanced customization is possible through the configuration files in `/lib/systemd/system/`.
|
||||
|
||||
In short, systemd is the current mainstream way to manage backend services on Linux, so I've abandoned `nohup` in my new versions of bash scripts, opting instead for systemd.
|
||||
|
||||
## 2. <a name='PrerequisitesRequiresrootpermissions'></a>Prerequisites (Requires root permissions)
|
||||
|
||||
1. Configure `environment.sh` based on the comments.
|
||||
2. Create a data directory:
|
||||
|
||||
```bash
|
||||
mkdir -p ${OPENIM_DATA_DIR}/{openim-api,openim-crontask}
|
||||
```
|
||||
|
||||
3. Create a bin directory and copy `openim-api` and `openim-crontask` executable files:
|
||||
|
||||
```bash
|
||||
source ./environment.sh
|
||||
mkdir -p ${OPENIM_INSTALL_DIR}/bin
|
||||
cp openim-api openim-crontask ${OPENIM_INSTALL_DIR}/bin
|
||||
```
|
||||
|
||||
4. Copy the configuration files of `openim-api` and `openim-crontask` to the `${OPENIM_CONFIG_DIR}` directory:
|
||||
|
||||
```bash
|
||||
mkdir -p ${OPENIM_CONFIG_DIR}
|
||||
cp openim-api.yaml openim-crontask.yaml ${OPENIM_CONFIG_DIR}
|
||||
```
|
||||
|
||||
## 3. <a name='Createopenim-apisystemdunittemplatefile'></a> Create `openim-api` systemd unit template file
|
||||
|
||||
For each OpenIM service, we will create a systemd unit template. Follow the steps below for each service:
|
||||
|
||||
Run the following shell script to generate the `openim-api.service.template`:
|
||||
|
||||
```bash
|
||||
source ./environment.sh
|
||||
cat > openim-api.service.template <<EOF
|
||||
[Unit]
|
||||
Description=OpenIM Server API
|
||||
Documentation=https://github.com/oepnimsdk/open-im-server-deploy/blob/master/init/README.md
|
||||
|
||||
[Service]
|
||||
WorkingDirectory=${OPENIM_DATA_DIR}/openim-api
|
||||
ExecStart=${OPENIM_INSTALL_DIR}/bin/openim-api --config=${OPENIM_CONFIG_DIR}/openim-api.yaml
|
||||
Restart=always
|
||||
RestartSec=5
|
||||
StartLimitInterval=0
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
EOF
|
||||
```
|
||||
|
||||
Following the above style, create the respective template files or generate them in bulk:
|
||||
|
||||
First, make sure you've sourced the environment variables:
|
||||
|
||||
```bash
|
||||
source ./environment.sh
|
||||
```
|
||||
|
||||
Use the shell script to generate the systemd unit template for each service:
|
||||
|
||||
```bash
|
||||
declare -a services=(
|
||||
"openim-api"
|
||||
... [other services]
|
||||
)
|
||||
|
||||
for service in "${services[@]}"
|
||||
do
|
||||
cat > $service.service.template <<EOF
|
||||
[Unit]
|
||||
Description=OpenIM Server - $service
|
||||
Documentation=https://github.com/oepnimsdk/open-im-server-deploy/blob/master/init/README.md
|
||||
|
||||
[Service]
|
||||
WorkingDirectory=${OPENIM_DATA_DIR}/$service
|
||||
ExecStart=${OPENIM_INSTALL_DIR}/bin/$service --config=${OPENIM_CONFIG_DIR}/$service.yaml
|
||||
Restart=always
|
||||
RestartSec=5
|
||||
StartLimitInterval=0
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
EOF
|
||||
done
|
||||
```
|
||||
|
||||
## 4. <a name='CopysystemdunittemplatefiletosystemdconfigdirectoryRequiresrootpermissions'></a>Copy systemd unit template file to systemd config directory (Requires root permissions)
|
||||
|
||||
Ensure you have root permissions to perform this operation:
|
||||
|
||||
```bash
|
||||
for service in "${services[@]}"
|
||||
do
|
||||
sudo cp $service.service.template /etc/systemd/system/$service.service
|
||||
done
|
||||
...
|
||||
```
|
||||
|
||||
## 5. <a name='Startsystemdservice'></a>Start systemd service
|
||||
|
||||
To start the OpenIM services:
|
||||
|
||||
```bash
|
||||
for service in "${services[@]}"
|
||||
do
|
||||
sudo systemctl daemon-reload
|
||||
sudo systemctl enable $service
|
||||
sudo systemctl restart $service
|
||||
done
|
||||
```
|
||||
162
docs/contrib/kafka.md
Normal file
162
docs/contrib/kafka.md
Normal file
@@ -0,0 +1,162 @@
|
||||
# OpenIM Kafka Guide
|
||||
|
||||
This document aims to provide a set of concise guidelines to help you quickly install and use Kafka through Docker Compose.
|
||||
|
||||
## Installing Kafka
|
||||
|
||||
With the Docker Compose script provided by OpenIM, you can easily install Kafka. Use the following command to start Kafka:
|
||||
|
||||
```bash
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
After executing this command, Kafka will be installed and started. You can confirm the Kafka container is running with the following command:
|
||||
|
||||
```bash
|
||||
docker ps | grep kafka
|
||||
```
|
||||
|
||||
The output of this command, as shown below, displays the status information of the Kafka container:
|
||||
|
||||
```
|
||||
be416b5a0851 bitnami/kafka:3.5.1 "/opt/bitnami/script…" 3 days ago Up 2 days 9092/tcp, 0.0.0.0:19094->9094/tcp, :::19094->9094/tcp kafka
|
||||
```
|
||||
|
||||
### References
|
||||
|
||||
- Official Docker installation documentation: [Click here](http://events.jianshu.io/p/b60afa35303a)
|
||||
- Detailed installation guide: [Tutorial on Towards Data Science](https://towardsdatascience.com/how-to-install-apache-kafka-using-docker-the-easy-way-4ceb00817d8b)
|
||||
|
||||
## Using Kafka
|
||||
|
||||
### Entering the Kafka Container
|
||||
|
||||
To execute Kafka commands, you first need to enter the Kafka container. Use the following command:
|
||||
|
||||
```bash
|
||||
docker exec -it kafka bash
|
||||
```
|
||||
|
||||
### Kafka Command Tools
|
||||
|
||||
Inside the Kafka container, you can use various command-line tools to manage Kafka. These tools include but are not limited to:
|
||||
|
||||
- `kafka-topics.sh`: For creating, deleting, listing, or altering topics.
|
||||
- `kafka-console-producer.sh`: Allows sending messages to a specified topic from the command line.
|
||||
- `kafka-console-consumer.sh`: Allows reading messages from the command line, with the ability to specify topics.
|
||||
- `kafka-consumer-groups.sh`: For managing consumer group information.
|
||||
|
||||
### Kafka Client Tool Installation
|
||||
|
||||
For easier Kafka management, you can install Kafka client tools. If you installed Kafka through OpenIM's Docker Compose, you can install the Kafka client tools with the following command:
|
||||
|
||||
```bash
|
||||
make install.kafkactl
|
||||
```
|
||||
|
||||
### Automatic Topic Creation
|
||||
|
||||
When installing Kafka through OpenIM's Docker Compose method, OpenIM automatically creates the following topics:
|
||||
|
||||
- `latestMsgToRedis`
|
||||
- `msgToPush`
|
||||
- `offlineMsgToMongoMysql`
|
||||
|
||||
These topics are created using the `scripts/create-topic.sh` script. The script waits for Kafka to be ready before executing the commands to create topics:
|
||||
|
||||
```bash
|
||||
# Wait for Kafka to be ready
|
||||
until /opt/bitnami/kafka/bin/kafka-topics.sh --list --bootstrap-server localhost:9092; do
|
||||
echo "Waiting for Kafka to be ready..."
|
||||
sleep 2
|
||||
done
|
||||
|
||||
# Create topics
|
||||
/opt/bitnami/kafka/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 8 --topic latestMsgToRedis
|
||||
/opt/bitnami/kafka/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 8 --topic msgToPush
|
||||
/opt/bitnami/kafka/bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 8 --topic offlineMsgToMongoMysql
|
||||
|
||||
echo "Topics created."
|
||||
```
|
||||
|
||||
The optimized and expanded documentation further details some basic commands for operations inside the Kafka container, as well as basic commands for managing Kafka using `kafkactl`. Here is a more detailed guide.
|
||||
|
||||
|
||||
## Basic Commands in the Kafka Container
|
||||
|
||||
### Listing Topics
|
||||
|
||||
To list all existing topics, you can use the following command:
|
||||
|
||||
```bash
|
||||
kafka-topics.sh --list --bootstrap-server localhost:9092
|
||||
```
|
||||
|
||||
### Creating a New Topic
|
||||
|
||||
When creating a new topic, you can specify the number of partitions and the replication factor. Here is the command to create a new topic:
|
||||
|
||||
```bash
|
||||
kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic your_topic_name
|
||||
```
|
||||
|
||||
### Producing Messages
|
||||
|
||||
To send messages to a specific topic, you can use the producer command. The following command prompts you to enter messages, which are sent to the specified topic with each press of the Enter key:
|
||||
|
||||
```bash
|
||||
kafka-console-producer.sh --broker-list localhost:9092 --topic your_topic_name
|
||||
```
|
||||
|
||||
### Consuming Messages
|
||||
|
||||
To read messages from a specific topic, you can use the consumer command. The following command reads new messages from the specified topic and outputs them on the console:
|
||||
|
||||
```bash
|
||||
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic your_topic_name --from-beginning
|
||||
```
|
||||
|
||||
The `
|
||||
|
||||
--from-beginning` parameter reads messages from the beginning of the topic. If this parameter is omitted, only new messages will be read.
|
||||
|
||||
|
||||
## Basic Commands Using `kafkactl`
|
||||
|
||||
`kafkactl` is a command-line tool for managing and operating Kafka clusters. It offers a more modern way to interact with Kafka.
|
||||
|
||||
### Listing Topics
|
||||
|
||||
To list all topics, you can use:
|
||||
|
||||
```bash
|
||||
kafkactl get topics
|
||||
```
|
||||
|
||||
### Creating a New Topic
|
||||
|
||||
To create a new topic with `kafkactl`, use:
|
||||
|
||||
```bash
|
||||
kafkactl create topic your_topic_name --partitions 1 --replication-factor 1
|
||||
```
|
||||
|
||||
### Producing Messages
|
||||
|
||||
To send messages to a topic, you can use:
|
||||
|
||||
```bash
|
||||
kafkactl produce your_topic_name --value "your message"
|
||||
```
|
||||
|
||||
Here, `"your message"` is the content of the message you want to send.
|
||||
|
||||
### Consuming Messages
|
||||
|
||||
To consume messages from a topic, use:
|
||||
|
||||
```bash
|
||||
kafkactl consume your_topic_name --from-beginning
|
||||
```
|
||||
|
||||
Again, the `--from-beginning` parameter will start consuming messages from the beginning of the topic. If you do not wish to start from the beginning, you can omit this parameter.
|
||||
137
docs/contrib/linux-development.md
Normal file
137
docs/contrib/linux-development.md
Normal file
@@ -0,0 +1,137 @@
|
||||
# Ubuntu 22.04 OpenIM Project Development Guide
|
||||
|
||||
## TOC
|
||||
- [Ubuntu 22.04 OpenIM Project Development Guide](#ubuntu-2204-openim-project-development-guide)
|
||||
- [TOC](#toc)
|
||||
- [1. Setting Up Ubuntu Server](#1-setting-up-ubuntu-server)
|
||||
- [1.1 Create `openim` Standard User](#11-create-openim-standard-user)
|
||||
- [1.2 Setting up the `openim` User's Shell Environment](#12-setting-up-the-openim-users-shell-environment)
|
||||
- [1.3 Installing Dependencies](#13-installing-dependencies)
|
||||
|
||||
## 1. Setting Up Ubuntu Server
|
||||
|
||||
You can use tools like PuTTY or other SSH clients to log in to your Ubuntu server. Once logged in, a few fundamental configurations are required, such as creating a standard user, adding to sudoers, and setting up the `$HOME/.bashrc` file. The steps are as follows:
|
||||
|
||||
## 1.1 Create `openim` Standard User
|
||||
|
||||
1. Log in to the Ubuntu system as the `root` user and create a standard user.
|
||||
|
||||
Generally, a project will involve multiple developers. Instead of provisioning a server for every developer, many organizations share a single development machine among developers. To simulate this real-world scenario, we'll use a standard user for development. To create the `openim` user:
|
||||
|
||||
```
|
||||
# adduser openim # Create the openim user, which developers will use for login and development.
|
||||
# passwd openim # Set the login password for openim.
|
||||
```
|
||||
|
||||
Working with a non-root user ensures the system's safety and is a good practice. It's recommended to avoid using the root user as much as possible during everyday development.
|
||||
|
||||
1. Add to sudoers.
|
||||
|
||||
Often, even standard users need root privileges. Instead of frequently asking the system administrator for the root password, you can add the standard user to the sudoers. This allows them to temporarily gain root access using the sudo command. To add the `openim` user to sudoers:
|
||||
|
||||
```
|
||||
|
||||
# sed -i '/^root.*ALL=(ALL:ALL).*ALL/a\openim\tALL=(ALL) \tALL' /etc/sudoers
|
||||
```
|
||||
|
||||
## 1.2 Setting up the `openim` User's Shell Environment
|
||||
|
||||
1. Log into the Ubuntu system.
|
||||
|
||||
Assuming we're using the **openim** user, log in using PuTTY or other SSH clients.
|
||||
|
||||
1. Configure the `$HOME/.bashrc` file.
|
||||
|
||||
The first step after logging into a new server is to configure the `$HOME/.bashrc` file. It makes the Linux shell more user-friendly by setting environment variables like `LANG` and `PS1`. Here's how the configuration would look:
|
||||
|
||||
```
|
||||
# .bashrc
|
||||
|
||||
# User specific aliases and functions
|
||||
|
||||
alias rm='rm -i'
|
||||
alias cp='cp -i'
|
||||
alias mv='mv -i'
|
||||
|
||||
# Source global definitions
|
||||
if [ -f /etc/bashrc ]; then
|
||||
. /etc/bashrc
|
||||
fi
|
||||
|
||||
if [ ! -d $HOME/workspace ]; then
|
||||
mkdir -p $HOME/workspace
|
||||
fi
|
||||
|
||||
# User specific environment
|
||||
export LANG="en_US.UTF-8"
|
||||
export PS1='[\u@dev \W]\$ '
|
||||
export WORKSPACE="$HOME/workspace"
|
||||
export PATH=$HOME/bin:$PATH
|
||||
|
||||
cd $WORKSPACE
|
||||
```
|
||||
|
||||
After updating `$HOME/.bashrc`, run the `bash` command to reload the configurations into the current shell.
|
||||
|
||||
## 1.3 Installing Dependencies
|
||||
|
||||
The OpenIM project on Ubuntu may have various dependencies. Some are direct, and others are indirect. Installing these in advance prevents issues like missing packages or compile-time errors later on.
|
||||
|
||||
1. Install dependencies.
|
||||
|
||||
You can use the `apt` command to install the required tools on Ubuntu:
|
||||
|
||||
```
|
||||
$ sudo apt-get update
|
||||
$ sudo apt-get install build-essential autoconf automake cmake perl libcurl4-gnutls-dev libtool gcc g++ glibc-doc-reference zlib1g-dev git-lfs telnet lrzsz jq libexpat1-dev libssl-dev
|
||||
$ sudo apt install libcurl4-openssl-dev
|
||||
```
|
||||
|
||||
1. Install Git.
|
||||
|
||||
A higher version of Git ensures compatibility with certain commands like `git fetch --unshallow`. To install a recent version:
|
||||
|
||||
```
|
||||
$ cd /tmp
|
||||
$ wget --no-check-certificate https://mirrors.edge.kernel.org/pub/software/scm/git/git-2.36.1.tar.gz
|
||||
$ tar -xvzf git-2.36.1.tar.gz
|
||||
$ cd git-2.36.1/
|
||||
$ ./configure
|
||||
$ make
|
||||
$ sudo make install
|
||||
$ git --version
|
||||
```
|
||||
|
||||
Then, add Git's binary directory to the `PATH`:
|
||||
|
||||
```
|
||||
|
||||
$ echo 'export PATH=/usr/local/libexec/git-core:$PATH' >> $HOME/.bashrc
|
||||
```
|
||||
|
||||
1. Configure Git.
|
||||
|
||||
To set up Git:
|
||||
|
||||
```
|
||||
$ git config --global user.name "Your Name"
|
||||
$ git config --global user.email "your_email@example.com"
|
||||
$ git config --global credential.helper store
|
||||
$ git config --global core.longpaths true
|
||||
```
|
||||
|
||||
Other Git configurations include:
|
||||
|
||||
```
|
||||
|
||||
$ git config --global core.quotepath off
|
||||
```
|
||||
|
||||
And for handling larger files:
|
||||
|
||||
```
|
||||
|
||||
$ git lfs install --skip-repo
|
||||
```
|
||||
|
||||
By following the steps in this guide, your Ubuntu 22.04 server should now be set up and ready for OpenIM project development.
|
||||
14
docs/contrib/local-actions.md
Normal file
14
docs/contrib/local-actions.md
Normal file
@@ -0,0 +1,14 @@
|
||||
# act
|
||||
|
||||
Run your [GitHub Actions](https://developer.github.com/actions/) locally! Why would you want to do this? Two reasons:
|
||||
|
||||
- **Fast Feedback** - Rather than having to commit/push every time you want to test out the changes you are making to your `.github/workflows/` files (or for any changes to embedded GitHub actions), you can use `act` to run the actions locally. The [environment variables](https://help.github.com/en/actions/configuring-and-managing-workflows/using-environment-variables#default-environment-variables) and [filesystem](https://help.github.com/en/actions/reference/virtual-environments-for-github-hosted-runners#filesystems-on-github-hosted-runners) are all configured to match what GitHub provides.
|
||||
- **Local Task Runner** - I love [make](https://en.wikipedia.org/wiki/Make_(software)). However, I also hate repeating myself. With `act`, you can use the GitHub Actions defined in your `.github/workflows/` to replace your `Makefile`!
|
||||
|
||||
## install act
|
||||
|
||||
+ [https://github.com/nektos/act](https://github.com/nektos/act)
|
||||
|
||||
```bash
|
||||
curl -s https://raw.githubusercontent.com/nektos/act/master/install.sh | sudo bash
|
||||
···
|
||||
507
docs/contrib/logging.md
Normal file
507
docs/contrib/logging.md
Normal file
@@ -0,0 +1,507 @@
|
||||
# OpenIM Logging and Error Handling Documentation
|
||||
|
||||
## Script Logging Documentation Link
|
||||
|
||||
If you wish to view the script's logging documentation, you can click on this link: [Logging Documentation](https://github.com/openimsdk/open-im-server-deploy/blob/main/docs/contrib/bash-log.md).
|
||||
|
||||
Below is the documentation for logging and error handling in the OpenIM Go project.
|
||||
|
||||
To create a standard set of documentation that is quick to read and easy to understand, we will highlight key information about the `Logger` interface and the `CodeError` interface. This includes the purpose of each interface, key methods, and their use cases. This will help developers quickly grasp how to effectively use logging and error handling within the project.
|
||||
|
||||
## Logging (`Logger` Interface)
|
||||
|
||||
### Purpose
|
||||
The `Logger` interface aims to provide the OpenIM project with a unified and flexible logging mechanism, supporting structured logging formats for efficient log management and analysis.
|
||||
|
||||
### Key Methods
|
||||
|
||||
- **Debug, Info, Warn, Error**
|
||||
Log messages of different levels to suit various logging needs and scenarios. These methods accept a context (`context.Context`), a message (`string`), and key-value pairs (`...interface{}`), allowing the log to carry rich context information.
|
||||
|
||||
- **WithValues**
|
||||
Append key-value pair information to log messages, returning a new `Logger` instance. This helps in adding consistent context information.
|
||||
|
||||
- **WithName**
|
||||
Set the name of the logger, which helps in identifying the source of the logs.
|
||||
|
||||
- **WithCallDepth**
|
||||
Adjust the call stack depth to accurately identify the source of the log message.
|
||||
|
||||
### Use Cases
|
||||
|
||||
- Developers should choose the appropriate logging level (such as `Debug`, `Info`, `Warn`, `Error`) based on the importance of the information when logging.
|
||||
- Use `WithValues` and `WithName` to add richer context information to logs, facilitating subsequent tracking and analysis.
|
||||
|
||||
## Error Handling (`CodeError` Interface)
|
||||
|
||||
### Purpose
|
||||
The `CodeError` interface is designed to provide a unified mechanism for error handling and wrapping, making error information more detailed and manageable.
|
||||
|
||||
### Key Methods
|
||||
|
||||
- **Code**
|
||||
Return the error code to distinguish between different types of errors.
|
||||
|
||||
- **Msg**
|
||||
Return the error message description to display to the user.
|
||||
|
||||
- **Detail**
|
||||
Return detailed information about the error for further debugging by developers.
|
||||
|
||||
- **WithDetail**
|
||||
Add detailed information to the error, returning a new `CodeError` instance.
|
||||
|
||||
- **Is**
|
||||
Determine whether the current error matches a specified error, supporting a flexible error comparison mechanism.
|
||||
|
||||
- **Wrap**
|
||||
Wrap another error with additional message description, facilitating the tracing of the error's cause.
|
||||
|
||||
### Use Cases
|
||||
|
||||
- When defining errors with specific codes and messages, use error types that implement the `CodeError` interface.
|
||||
- Use `WithDetail` to add additional context information to errors for more accurate problem localization.
|
||||
- Use the `Is` method to judge the type of error for conditional branching.
|
||||
- Use the `Wrap` method to wrap underlying errors while adding more contextual descriptions.
|
||||
|
||||
## Logging Standards and Code Examples
|
||||
|
||||
In the OpenIM project, we use the unified logging package `github.com/openimsdk/tools/log` for logging to achieve efficient log management and analysis. This logging package supports structured logging formats, making it easier for developers to handle log information.
|
||||
|
||||
### Logger Interface and Implementation
|
||||
|
||||
The logger interface is defined as follows:
|
||||
|
||||
```go
|
||||
type Logger interface {
|
||||
Debug(ctx context.Context, msg string, keysAndValues ...interface{})
|
||||
Info(ctx context.Context, msg string, keysAndValues ...interface{})
|
||||
Warn(ctx context.Context, msg string, err error, keysAndValues ...interface{})
|
||||
Error(ctx context.Context, msg string, err error, keysAndValues ...interface{})
|
||||
WithValues(keysAndValues ...interface{}) Logger
|
||||
WithName(name string) Logger
|
||||
WithCallDepth(depth int) Logger
|
||||
}
|
||||
```
|
||||
|
||||
Example code: Using the `Logger` interface to log at the info level.
|
||||
|
||||
```go
|
||||
func main() {
|
||||
logger := log.NewLogger().WithName("MyService")
|
||||
ctx := context.Background()
|
||||
logger.Info(ctx, "Service started", "port", "8080")
|
||||
}
|
||||
```
|
||||
|
||||
## Error Handling and Code Examples
|
||||
|
||||
We use the `github.com/openimsdk/tools/errs` package for unified error handling and wrapping.
|
||||
|
||||
### CodeError Interface and Implementation
|
||||
|
||||
The error interface is defined as follows:
|
||||
|
||||
```go
|
||||
type CodeError interface {
|
||||
Code() int
|
||||
Msg() string
|
||||
Detail() string
|
||||
WithDetail(detail string) CodeError
|
||||
Is(err error, loose ...bool) bool
|
||||
Wrap(msg ...string) error
|
||||
error
|
||||
}
|
||||
```
|
||||
|
||||
Example code: Creating and using the `CodeError` interface to handle errors.
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"github.com/openimsdk/tools/errs"
|
||||
)
|
||||
|
||||
func main() {
|
||||
err := errs.New(404, "Resource not found")
|
||||
err = err.WithDetail("
|
||||
|
||||
More details")
|
||||
if e, ok := err.(errs.CodeError); ok {
|
||||
fmt.Println(e.Code(), e.Msg(), e.Detail())
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Detailed Logging Standards and Code Examples
|
||||
|
||||
1. **Print key information at startup**
|
||||
It is crucial to print entry parameters and key process information at program startup. This helps understand the startup state and configuration of the program.
|
||||
|
||||
**Code Example**:
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
)
|
||||
|
||||
func main() {
|
||||
fmt.Println("Program startup, version: 1.0.0")
|
||||
fmt.Printf("Connecting to database: %s\n", os.Getenv("DATABASE_URL"))
|
||||
}
|
||||
```
|
||||
|
||||
2. **Use `tools/log` and `fmt` for logging**
|
||||
Logging should be done using a specialized logging library for unified management and formatted log output.
|
||||
|
||||
**Code Example**: Logging an info level message with `tools/log`.
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"context"
|
||||
"github.com/openimsdk/tools/log"
|
||||
)
|
||||
|
||||
func main() {
|
||||
ctx := context.Background()
|
||||
log.Info(ctx, "Application started successfully")
|
||||
}
|
||||
```
|
||||
|
||||
3. **Use standard error output for startup failures or critical information**
|
||||
Critical error messages or program startup failures should be indicated to the user through standard error output.
|
||||
|
||||
**Code Example**:
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"os"
|
||||
)
|
||||
|
||||
func checkEnvironment() bool {
|
||||
return os.Getenv("REQUIRED_ENV") != ""
|
||||
}
|
||||
|
||||
func main() {
|
||||
if !checkEnvironment() {
|
||||
fmt.Fprintln(os.Stderr, "Missing required environment variable")
|
||||
os.Exit(1)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
We encapsulate it into separate tools, which can output error information through the `tools/log` package.
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
util "git.imall.cloud/openim/open-im-server-deploy/pkg/util/genutil"
|
||||
)
|
||||
|
||||
func main() {
|
||||
if err := apiCmd.Execute(); err != nil {
|
||||
util.ExitWithError(err)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
4. **Use `tools/log` package for runtime logging**
|
||||
This ensures consistency and control over logging.
|
||||
|
||||
**Code Example**: Same as the above example using `tools/log`. When `tools/log` is not initialized, consider using `fmt` for standard output.
|
||||
|
||||
5. **Error logs should be printed by the top-level caller**
|
||||
This is to avoid duplicate logging of errors, typically errors are caught and logged at the application's outermost level.
|
||||
|
||||
**Code Example**:
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"github.com/openimsdk/tools/log"
|
||||
"context"
|
||||
)
|
||||
|
||||
func doSomething() error {
|
||||
// An error occurs here
|
||||
return errs.Wrap(errors.New("An error occurred"))
|
||||
}
|
||||
|
||||
func controller() error {
|
||||
err := doSomething()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func main() {
|
||||
err := controller()
|
||||
if err != nil {
|
||||
log.Error(context.Background(), "Operation failed", err)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
6. **Handling logs for API RPC calls and non-RPC applications**
|
||||
|
||||
For API RPC calls using gRPC, logs at the information level are printed by middleware on the gRPC server side, reducing the need to manually log in each RPC method. For non-RPC applications, it's recommended to manually log key execution paths to track the application's execution flow.
|
||||
|
||||
**gRPC Server-Side Logging Middleware:**
|
||||
|
||||
In gRPC, `UnaryInterceptor` and `StreamInterceptor` can intercept Unary and Stream type RPC calls, respectively. Here's an example of how to implement a simple Unary RPC logging middleware:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"context"
|
||||
"google.golang.org/grpc"
|
||||
"google.golang.org/grpc/codes"
|
||||
"google.golang.org/grpc/status"
|
||||
"log"
|
||||
"time"
|
||||
)
|
||||
|
||||
// unaryServerInterceptor returns a new unary server interceptor that logs each request.
|
||||
func unaryServerInterceptor() grpc.UnaryServerInterceptor {
|
||||
return func(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{}, err error) {
|
||||
// Record the start time of the request
|
||||
start := time.Now()
|
||||
// Call the actual RPC method
|
||||
resp, err = handler(ctx, req)
|
||||
// After the request ends, log the duration and other information
|
||||
log.Printf("Request method: %s, duration: %s, error status: %v", info.FullMethod, time.Since(start), status.Code(err))
|
||||
return resp, err
|
||||
}
|
||||
}
|
||||
|
||||
func main() {
|
||||
// Create a gRPC server and add the middleware
|
||||
s := grpc.NewServer
|
||||
|
||||
(grpc.UnaryInterceptor(unaryServerInterceptor()))
|
||||
// Register your service
|
||||
|
||||
// Start the gRPC server
|
||||
log.Println("Starting gRPC server...")
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
**Logging for Non-RPC Applications:**
|
||||
|
||||
For non-RPC applications, the key is to log at appropriate places in the code to maintain an execution trace. Here's a simple example showing how to log when handling a task:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"log"
|
||||
)
|
||||
|
||||
func processTask(taskID string) {
|
||||
// Log the start of task processing
|
||||
log.Printf("Starting task processing: %s", taskID)
|
||||
// Suppose this is where the task is processed
|
||||
|
||||
// Log after the task is completed
|
||||
log.Printf("Task processing completed: %s", taskID)
|
||||
}
|
||||
|
||||
func main() {
|
||||
// Example task ID
|
||||
taskID := "task123"
|
||||
processTask(taskID)
|
||||
}
|
||||
```
|
||||
|
||||
In both scenarios, appropriate logging can help developers and operators monitor the health of the system, trace the source of issues, and quickly locate and resolve problems. For gRPC logging, using middleware can effectively centralize log management and control. For non-RPC applications, ensuring logs are placed at critical execution points can help understand the program's operational flow and state changes.
|
||||
|
||||
### When to Wrap Errors?
|
||||
|
||||
1. **Wrap errors generated within the function**
|
||||
When an error occurs within a function, use `errs.Wrap` to add context information to the original error.
|
||||
|
||||
**Code Example**:
|
||||
```go
|
||||
func doSomething() error {
|
||||
// Suppose an error occurs here
|
||||
err, _ := someFunc()
|
||||
if err != nil {
|
||||
return errs.WrapMsg(err, "doSomething failed")
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
It just works if the package is wrong:
|
||||
|
||||
```go
|
||||
func doSomething() error {
|
||||
// Suppose an error occurs here
|
||||
err, _ := someFunc()
|
||||
if err != nil {
|
||||
return errs.Wrap(err)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
2. **Wrap errors from system calls or other packages**
|
||||
When calling external libraries or system functions that return errors, also add context information to wrap the error.
|
||||
|
||||
**Code Example**:
|
||||
```go
|
||||
func readConfig(file string) error {
|
||||
_, err := os.ReadFile(file)
|
||||
if err != nil {
|
||||
return errs.Wrap(err, "Failed to read config file")
|
||||
}
|
||||
return nil
|
||||
}
|
||||
```
|
||||
|
||||
3. **No need to re-wrap errors for internal module calls**
|
||||
|
||||
If an error has been appropriately wrapped with sufficient context information in an internal module call, there's no need to wrap it again.
|
||||
|
||||
**Code Example**:
|
||||
```go
|
||||
func doSomething() error {
|
||||
err := doAnotherThing()
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
```
|
||||
|
||||
4. **Ensure comprehensive wrapping of errors with detailed messages**
|
||||
When wrapping errors, ensure to provide ample context information to make the error more understandable and easier to debug.
|
||||
|
||||
**Code Example**:
|
||||
```go
|
||||
func connectDatabase() error {
|
||||
err := db.Connect(config.DatabaseURL)
|
||||
if err != nil {
|
||||
return errs.Wrap(err, fmt.Sprintf("Failed to connect to database, URL: %s", config.DatabaseURL))
|
||||
}
|
||||
return nil
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
### About WrapMsg Use
|
||||
|
||||
```go
|
||||
// "github.com/openimsdk/tools/errs"
|
||||
func WrapMsg(err error, msg string, kv ...any) error {
|
||||
if len(kv) == 0 {
|
||||
if len(msg) == 0 {
|
||||
return errors.WithStack(err)
|
||||
} else {
|
||||
return errors.WithMessage(err, msg)
|
||||
}
|
||||
}
|
||||
var buf bytes.Buffer
|
||||
if len(msg) > 0 {
|
||||
buf.WriteString(msg)
|
||||
buf.WriteString(" ")
|
||||
}
|
||||
for i := 0; i < len(kv); i += 2 {
|
||||
if i > 0 {
|
||||
buf.WriteString(", ")
|
||||
}
|
||||
buf.WriteString(toString(kv[i]))
|
||||
buf.WriteString("=")
|
||||
buf.WriteString(toString(kv[i+1]))
|
||||
}
|
||||
return errors.WithMessage(err, buf.String())
|
||||
}
|
||||
```
|
||||
|
||||
1. **Function Signature**:
|
||||
- `err error`: The original error object.
|
||||
- `msg string`: The message text to append to the error.
|
||||
- `kv ...any`: A variable number of parameters used to pass key-value pairs. `any` was introduced in Go 1.18 and is equivalent to `interface{}`, meaning any type.
|
||||
|
||||
2. **Logic**:
|
||||
- If there are no key-value pairs (`kv` is empty):
|
||||
- If `msg` is also empty, use `errors.WithStack(err)` to return the original error with the call stack appended.
|
||||
- If `msg` is not empty, use `errors.WithMessage(err, msg)` to append the message text to the original error.
|
||||
- If there are key-value pairs, the function constructs a string containing the message text and all key-value pairs. The key-value pairs are added in the format `"key=value"`, separated by commas. If a message text is provided, it is added first, followed by a space.
|
||||
|
||||
3. **Key-Value Pair Formatting**:
|
||||
- A loop iterates over all the key-value pairs, processing one pair at a time.
|
||||
- The `toString` function (although not provided in the code, we can assume it converts any type to a string) is used to convert both keys and values to strings, and they are added to a `bytes.Buffer` in the format `"key=value"`.
|
||||
|
||||
4. **Result**:
|
||||
- Use `errors.WithMessage(err, buf.String())` to append the constructed message text to the original error, and return this new error object.
|
||||
|
||||
Next, let's demonstrate several ways to use the `WrapMsg` function:
|
||||
|
||||
**Example 1: No Additional Information**
|
||||
|
||||
```go
|
||||
// "github.com/openimsdk/tools/errs"
|
||||
err := errors.New("original error")
|
||||
wrappedErr := errs.WrapMsg(err, "")
|
||||
// wrappedErr will contain the original error and its call stack
|
||||
```
|
||||
|
||||
**Example 2: Message Text Only**
|
||||
|
||||
```go
|
||||
// "github.com/openimsdk/tools/errs"
|
||||
err := errors.New("original error")
|
||||
wrappedErr := errs.WrapMsg(err, "additional error information")
|
||||
// wrappedErr will contain the original error, call stack, and "additional error information"
|
||||
```
|
||||
|
||||
**Example 3: Message Text and Key-Value Pairs**
|
||||
|
||||
```go
|
||||
// "github.com/openimsdk/tools/errs"
|
||||
err := errors.New("original error")
|
||||
wrappedErr := errs.WrapMsg(err, "problem occurred", "code", 404, "url", "webhook://example.com")
|
||||
// wrappedErr will contain the original error, call stack, and "problem occurred code=404, url=http://example.com"
|
||||
```
|
||||
|
||||
**Example 4: Key-Value Pairs Only**
|
||||
|
||||
```go
|
||||
// "github.com/openimsdk/tools/errs"
|
||||
err := errors.New("original error")
|
||||
wrappedErr := errs.WrapMsg(err, "", "user", "john_doe", "action", "login")
|
||||
// wrappedErr will contain the original error, call stack, and "user=john_doe, action=login"
|
||||
```
|
||||
|
||||
> [!TIP] WThese examples demonstrate how the `errs.WrapMsg` function can flexibly handle error messages and context data, helping developers to more effectively track and debug their programs.
|
||||
|
||||
|
||||
### Example 5: Dynamic Key-Value Pairs from Context
|
||||
Suppose we have some runtime context variables, such as a user ID and the type of operation being performed, and we want to include these variables in the error message. This can help with later debugging and identifying the specific environment of the issue.
|
||||
|
||||
```go
|
||||
// Define some context variables
|
||||
userID := "user123"
|
||||
operation := "update profile"
|
||||
errorCode := 500
|
||||
requestURL := "webhook://example.com/updateProfile"
|
||||
|
||||
// Create a new error
|
||||
err := errors.New("original error")
|
||||
|
||||
// Wrap the error, including dynamic key-value pairs from the context
|
||||
wrappedErr := errs.WrapMsg(err, "operation failed", "user", userID, "action", operation, "code", errorCode, "url", requestURL)
|
||||
// wrappedErr will contain the original error, call stack, and "operation failed user=user123, action=update profile, code=500, url=http://example.com/updateProfile"
|
||||
```
|
||||
|
||||
> [!TIP]In this example, the `WrapMsg` function accepts not just a static error message and additional information, but also dynamic key-value pairs generated from the code's execution context, such as the user ID, operation type, error code, and the URL of the request. Including this contextual information in the error message makes it easier for developers to understand and resolve the issue.
|
||||
258
docs/contrib/mac-developer-deployment-guide.md
Normal file
258
docs/contrib/mac-developer-deployment-guide.md
Normal file
@@ -0,0 +1,258 @@
|
||||
# Mac Developer Deployment Guide for OpenIM
|
||||
|
||||
## Introduction
|
||||
|
||||
This guide aims to assist Mac-based developers in contributing effectively to OpenIM. It covers the setup of a development environment tailored for Mac, including the use of GitHub for development workflow and `devcontainer` for a consistent development experience.
|
||||
|
||||
Before contributing to OpenIM through issues and pull requests, make sure you are familiar with GitHub and the [pull request workflow](https://docs.github.com/en/get-started/quickstart/github-flow).
|
||||
|
||||
## Prerequisites
|
||||
|
||||
### System Requirements
|
||||
|
||||
- macOS (latest stable version recommended)
|
||||
- Internet connection
|
||||
- Administrator access
|
||||
|
||||
### Knowledge Requirements
|
||||
|
||||
- Basic understanding of Git and GitHub
|
||||
- Familiarity with Docker and containerization
|
||||
- Experience with Go programming language
|
||||
|
||||
## Setting up the Development Environment
|
||||
|
||||
### Installing Homebrew
|
||||
|
||||
Homebrew is an essential package manager for macOS. Install it using:
|
||||
|
||||
```sh
|
||||
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
|
||||
```
|
||||
|
||||
### Installing and Configuring Git
|
||||
|
||||
1. Install Git:
|
||||
|
||||
```sh
|
||||
brew install git
|
||||
```
|
||||
|
||||
2. Configure Git with your user details:
|
||||
|
||||
```sh
|
||||
git config --global user.name "Your Name"
|
||||
git config --global user.email "your.email@example.com"
|
||||
```
|
||||
|
||||
### Setting Up the Devcontainer
|
||||
|
||||
`Devcontainers` provide a Docker-based isolated development environment.
|
||||
|
||||
Read [README.md](https://github.com/openimsdk/open-im-server-deploy/tree/main/.devcontainer) in the `.devcontainer` directory of the project to learn more about the devcontainer.
|
||||
|
||||
To set it up:
|
||||
|
||||
1. Install Docker Desktop for Mac from [Docker Hub](https://docs.docker.com/desktop/install/mac-install/).
|
||||
2. Install Visual Studio Code and the Remote - Containers extension.
|
||||
3. Open the cloned OpenIM repository in VS Code.
|
||||
4. VS Code will prompt to reopen the project in a container. Accept this to set up the environment automatically.
|
||||
|
||||
### Installing Go and Dependencies
|
||||
|
||||
Use Homebrew to install Go:
|
||||
|
||||
```sh
|
||||
brew install go
|
||||
```
|
||||
|
||||
Ensure the version of Go is compatible with the version required by OpenIM (refer to the main documentation for version requirements).
|
||||
|
||||
### Additional Tools
|
||||
|
||||
Install other required tools like Docker, Vagrant, and necessary GNU utils as described in the main documentation.
|
||||
|
||||
## Mac Deployment openim-chat and openim-server
|
||||
|
||||
To integrate the Chinese document into an English document for Linux deployment, we will first translate the content and then adapt it to suit the Linux environment. Here's how the translated and adapted content might look:
|
||||
|
||||
### Ensure a Clean Environment
|
||||
|
||||
- It's recommended to execute in a new directory.
|
||||
- Run `ps -ef | grep openim` to ensure no OpenIM processes are running.
|
||||
- Run `ps -ef | grep chat` to check for absence of chat-related processes.
|
||||
- Execute `docker ps` to verify there are no related containers running.
|
||||
|
||||
### Source Code Deployment
|
||||
|
||||
#### Deploying openim-server
|
||||
|
||||
Source code deployment is slightly more complex because Docker's networking on Linux differs from Mac.
|
||||
|
||||
```bash
|
||||
git clone https://github.com/openimsdk/open-im-server-deploy
|
||||
cd open-im-server-deploy
|
||||
|
||||
export OPENIM_IP="Your IP" # If it's a cloud server, setting might not be needed
|
||||
make init # Generates configuration files
|
||||
```
|
||||
|
||||
Before deploying openim-server, modify the Kafka logic in the docker-compose.yml file. Replace:
|
||||
|
||||
```yaml
|
||||
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://${DOCKER_BRIDGE_GATEWAY:-172.28.0.1}:${KAFKA_PORT:-19094}
|
||||
```
|
||||
|
||||
With:
|
||||
|
||||
```yaml
|
||||
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://127.0.0.1:${KAFKA_PORT:-19094}
|
||||
```
|
||||
|
||||
Then start the service:
|
||||
|
||||
```bash
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
Before starting the openim-server source, set `config/config.yaml` by replacing all instances of `172.28.0.1` with `127.0.0.1`:
|
||||
|
||||
```bash
|
||||
vim config/config.yaml -c "%s/172\.28\.0\.1/127.0.0.1/g" -c "wq"
|
||||
```
|
||||
|
||||
Then start openim-server:
|
||||
|
||||
```bash
|
||||
make start
|
||||
```
|
||||
|
||||
To check the startup:
|
||||
|
||||
```bash
|
||||
make check
|
||||
```
|
||||
|
||||
<aside>
|
||||
🚧 To avoid mishaps, it's best to wait five minutes before running `make check` again.
|
||||
|
||||
</aside>
|
||||
|
||||
#### Deploying openim-chat
|
||||
|
||||
There are several ways to deploy openim-chat, either by source code or using Docker.
|
||||
|
||||
Navigate back to the parent directory:
|
||||
|
||||
```bash
|
||||
cd ..
|
||||
```
|
||||
|
||||
First, let's look at deploying chat from source:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/openimsdk/chat
|
||||
cd chat
|
||||
make init # Generates configuration files
|
||||
```
|
||||
|
||||
If openim-chat has not deployed MySQL, you will need to deploy it. Note that the official Docker Hub for MySQL does not support architectures like ARM, so you can use the newer version of the open-source edition:
|
||||
|
||||
```bash
|
||||
docker run -d \
|
||||
--name mysql \
|
||||
-p 13306:3306 \
|
||||
-p 3306:33060 \
|
||||
-v "$(pwd)/components/mysql/data:/var/lib/mysql" \
|
||||
-v "/etc/localtime:/etc/localtime" \
|
||||
-e MYSQL_ROOT_PASSWORD="openIM123" \
|
||||
--restart always \
|
||||
mariadb:10.6
|
||||
```
|
||||
|
||||
Before starting the source code of openim-chat, set `config/config.yaml` by replacing all instances of `172.28.0.1` with `127.0.0.1`:
|
||||
|
||||
```bash
|
||||
vim config/config.yaml -c "%s/172\.28\.0\.1/127.0.0.1/g" -c "wq"
|
||||
```
|
||||
|
||||
Then start openim-chat from source:
|
||||
|
||||
```bash
|
||||
make start
|
||||
```
|
||||
|
||||
To check, ensure the following four processes start successfully:
|
||||
|
||||
```bash
|
||||
make check
|
||||
```
|
||||
|
||||
### Docker Deployment
|
||||
|
||||
Refer to https://github.com/openimsdk/openim-docker for Docker deployment instructions, which can be followed similarly on Linux.
|
||||
|
||||
```bash
|
||||
git clone https://github.com/openimsdk/openim-docker
|
||||
cd openim-docker
|
||||
export OPENIM_IP="Your IP"
|
||||
make init
|
||||
docker compose up -d
|
||||
docker compose logs -f openim-server
|
||||
docker compose logs -f openim-chat
|
||||
```
|
||||
|
||||
## GitHub Development Workflow
|
||||
|
||||
### Creating a New Branch
|
||||
|
||||
For new features or fixes, create a new branch:
|
||||
|
||||
```sh
|
||||
git checkout -b feat/your-feature-name
|
||||
```
|
||||
|
||||
### Making Changes and Committing
|
||||
|
||||
1. Make your changes in the code.
|
||||
2. Stage your changes:
|
||||
|
||||
```sh
|
||||
git add .
|
||||
```
|
||||
|
||||
3. Commit with a meaningful message:
|
||||
|
||||
```sh
|
||||
git commit -m "Add a brief description of your changes"
|
||||
```
|
||||
|
||||
### Pushing Changes and Creating Pull Requests
|
||||
|
||||
1. Push your branch to GitHub:
|
||||
|
||||
```sh
|
||||
git push origin feat/your-feature-name
|
||||
```
|
||||
|
||||
2. Go to your fork on GitHub and create a pull request to the main OpenIM repository.
|
||||
|
||||
### Keeping Your Fork Updated
|
||||
|
||||
Regularly sync your fork with the main repository:
|
||||
|
||||
```sh
|
||||
git fetch upstream
|
||||
git checkout main
|
||||
git rebase upstream/main
|
||||
```
|
||||
|
||||
More read: [https://github.com/openimsdk/open-im-server-deploy/blob/main/CONTRIBUTING.md](https://github.com/openimsdk/open-im-server-deploy/blob/main/CONTRIBUTING.md)
|
||||
|
||||
## Testing and Quality Assurance
|
||||
|
||||
Run tests as described in the OpenIM documentation to ensure your changes do not break existing functionality.
|
||||
|
||||
## Conclusion
|
||||
|
||||
This guide provides a comprehensive overview for Mac developers to set up and contribute to OpenIM. By following these steps, you can ensure a smooth and efficient development experience. Happy coding!
|
||||
178
docs/contrib/offline-deployment.md
Normal file
178
docs/contrib/offline-deployment.md
Normal file
@@ -0,0 +1,178 @@
|
||||
# OpenIM Offline Deployment Design
|
||||
|
||||
## 1. Base Images
|
||||
|
||||
Below are the base images and their versions you'll need:
|
||||
|
||||
- [ ] bitnami/kafka:3.5.1
|
||||
- [ ] redis:7.0.0
|
||||
- [ ] mongo:6.0.2
|
||||
- [ ] bitnami/zookeeper:3.8
|
||||
- [ ] minio/minio:RELEASE.2024-01-11T07-46-16Z
|
||||
|
||||
> [!IMPORTANT]
|
||||
> It is important to note that OpenIM removed mysql components from versions v3.5.0 (release-v3.5) and above, so mysql can be deployed without this requirement or above
|
||||
|
||||
**If you need to install more IM components or monitoring products:**
|
||||
|
||||
OpenIM:
|
||||
|
||||
> [!TIP]
|
||||
> If you need to install more IM components or monitoring products [images.md](https://github.com/openimsdk/open-im-server-deploy/blob/main/docs/contrib/images.md)
|
||||
|
||||
- [ ] ghcr.io/openimsdk/openim-web:<version-name>
|
||||
- [ ] ghcr.io/openimsdk/openim-admin:<version-name>
|
||||
- [ ] ghcr.io/openimsdk/openim-chat:<version-name>
|
||||
- [ ] ghcr.io/openimsdk/openim-server:<version-name>
|
||||
|
||||
|
||||
Monitoring:
|
||||
|
||||
- [ ] prom/prometheus:v2.48.1
|
||||
- [ ] prom/alertmanager:v0.23.0
|
||||
- [ ] grafana/grafana:10.2.2
|
||||
- [ ] bitnami/node-exporter:1.7.0
|
||||
|
||||
|
||||
Use the following commands to pull these base images:
|
||||
|
||||
```bash
|
||||
docker pull bitnami/kafka:3.5.1
|
||||
docker pull redis:7.0.0
|
||||
docker pull mongo:6.0.2
|
||||
docker pull mariadb:10.6
|
||||
docker pull bitnami/zookeeper:3.8
|
||||
docker pull minio/minio:2024-01-11T07-46-16Z
|
||||
```
|
||||
|
||||
If you need to install more IM components or monitoring products:
|
||||
|
||||
```bash
|
||||
docker pull prom/prometheus:v2.48.1
|
||||
docker pull prom/alertmanager:v0.23.0
|
||||
docker pull grafana/grafana:10.2.2
|
||||
docker pull bitnami/node-exporter:1.7.0
|
||||
```
|
||||
|
||||
## 2. OpenIM Images
|
||||
|
||||
**For detailed understanding of version management and storage of OpenIM and Chat**: [version.md](https://github.com/openimsdk/open-im-server-deploy/blob/main/docs/contrib/version.md)
|
||||
|
||||
### OpenIM Image
|
||||
|
||||
- Get image version info: [images.md](https://github.com/openimsdk/open-im-server-deploy/blob/main/docs/contrib/images.md)
|
||||
- Depending on the required version, execute the following command:
|
||||
|
||||
```bash
|
||||
docker pull ghcr.io/openimsdk/openim-server:<version-name>
|
||||
```
|
||||
|
||||
### Chat Image
|
||||
|
||||
- Execute the following command to pull the image:
|
||||
|
||||
```bash
|
||||
docker pull ghcr.io/openimsdk/openim-chat:<version-name>
|
||||
```
|
||||
|
||||
### Web Image
|
||||
|
||||
- Execute the following command to pull the image:
|
||||
|
||||
```bash
|
||||
docker pull ghcr.io/openimsdk/openim-web:<version-name>
|
||||
```
|
||||
|
||||
### Admin Image
|
||||
|
||||
- Execute the following command to pull the image:
|
||||
|
||||
```bash
|
||||
docker pull ghcr.io/openimsdk/openim-admin:<version-name>
|
||||
```
|
||||
|
||||
|
||||
## 3. Image Storage Selection
|
||||
|
||||
**Repositories**:
|
||||
|
||||
- Alibaba Cloud: `registry.cn-hangzhou.aliyuncs.com/openimsdk/openim-server`
|
||||
- Docker Hub: `openim/openim-server`
|
||||
|
||||
**Version Selection**:
|
||||
|
||||
- Stable: e.g. release-v3.2 (or 3.1, 3.3)
|
||||
- Latest: latest
|
||||
- Latest of main: main
|
||||
|
||||
## 4. Version Selection
|
||||
|
||||
You can select from the following versions:
|
||||
|
||||
- Stable: e.g. release-v3.2
|
||||
- Latest: latest
|
||||
- Latest from main branch: main
|
||||
|
||||
## 5. Offline Deployment Steps
|
||||
|
||||
1. **Pull images**: Execute the above `docker pull` commands to pull all required images locally.
|
||||
2. **Save images**:
|
||||
|
||||
```bash
|
||||
docker save -o <tar-file-name>.tar <image-name>
|
||||
```
|
||||
|
||||
If you want to save all the images, use the following command:
|
||||
|
||||
```bash
|
||||
docker save -o <tar-file-name>.tar $(docker images -q)
|
||||
```
|
||||
|
||||
3. **Fetch code**: Clone the repository:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/openimsdk/openim-docker.git
|
||||
```
|
||||
|
||||
Or download the code from [Releases](https://github.com/openimsdk/openim-docker/releases/).
|
||||
|
||||
> Because of the difference between win and linux newlines, please do not clone the repository with win and then synchronize scp to linux.
|
||||
|
||||
4. **Transfer files**: Use `scp` to transfer all images and code to the intranet server.
|
||||
|
||||
```bash
|
||||
scp <tar-file-name>.tar user@remote-ip:/path/on/remote/server
|
||||
```
|
||||
|
||||
Or choose other transfer methods such as a hard drive.
|
||||
|
||||
5. **Import images**: On the intranet server:
|
||||
|
||||
```bash
|
||||
docker load -i <tar-file-name>.tar
|
||||
```
|
||||
|
||||
Import directly with shortcut commands:
|
||||
|
||||
```bash
|
||||
for i in `ls ./`;do docker load -i $i;done
|
||||
```
|
||||
|
||||
6. **Deploy**: Navigate to the `openim-docker` repository directory and follow the [README guide](https://github.com/openimsdk/openim-docker) for deployment.
|
||||
|
||||
7. **Deploy using docker compose**:
|
||||
|
||||
```bash
|
||||
export OPENIM_IP="your ip" # Set Ip
|
||||
make init # Init config
|
||||
docker compose up -d # Deployment
|
||||
docker compose ps # Verify
|
||||
```
|
||||
|
||||
> **Note**: If you're using a version of Docker prior to 20, make sure you've installed `docker-compose`.
|
||||
|
||||
## 6. Reference Links
|
||||
|
||||
- [openimsdk Issue #432](https://github.com/openimsdk/open-im-server-deploy/issues/432)
|
||||
- [Notion Link](https://nsddd.notion.site/435ee747c0bc44048da9300a2d745ad3?pvs=25)
|
||||
- [openimsdk Issue #474](https://github.com/openimsdk/open-im-server-deploy/issues/474)
|
||||
326
docs/contrib/prometheus-grafana.md
Normal file
326
docs/contrib/prometheus-grafana.md
Normal file
@@ -0,0 +1,326 @@
|
||||
# Deployment and Design of OpenIM's Management Backend and Monitoring
|
||||
|
||||
<!-- vscode-markdown-toc -->
|
||||
* 1. [Source Code & Docker](#SourceCodeDocker)
|
||||
* 1.1. [Deployment](#Deployment)
|
||||
* 1.2. [Configuration](#Configuration)
|
||||
* 1.3. [Monitoring Running in Docker Guide](#MonitoringRunninginDockerGuide)
|
||||
* 1.3.1. [Introduction](#Introduction)
|
||||
* 1.3.2. [Prerequisites](#Prerequisites)
|
||||
* 1.3.3. [Step 1: Clone the Repository](#Step1:ClonetheRepository)
|
||||
* 1.3.4. [Step 2: Start Docker Compose](#Step2:StartDockerCompose)
|
||||
* 1.3.5. [Step 3: Use the OpenIM Web Interface](#Step3:UsetheOpenIMWebInterface)
|
||||
* 1.3.6. [Running Effect](#RunningEffect)
|
||||
* 1.3.7. [Step 4: Access the Admin Panel](#Step4:AccesstheAdminPanel)
|
||||
* 1.3.8. [Step 5: Access the Monitoring Interface](#Step5:AccesstheMonitoringInterface)
|
||||
* 1.3.9. [Next Steps](#NextSteps)
|
||||
* 1.3.10. [Troubleshooting](#Troubleshooting)
|
||||
* 2. [Kubernetes](#Kubernetes)
|
||||
* 2.1. [Middleware Monitoring](#MiddlewareMonitoring)
|
||||
* 2.2. [Custom OpenIM Metrics](#CustomOpenIMMetrics)
|
||||
* 2.3. [Node Exporter](#NodeExporter)
|
||||
* 3. [Setting Up and Configuring AlertManager Using Environment Variables and `make init`](#SettingUpandConfiguringAlertManagerUsingEnvironmentVariablesandmakeinit)
|
||||
* 3.1. [Introduction](#Introduction-1)
|
||||
* 3.2. [Prerequisites](#Prerequisites-1)
|
||||
* 3.3. [Configuration Steps](#ConfigurationSteps)
|
||||
* 3.3.1. [Exporting Environment Variables](#ExportingEnvironmentVariables)
|
||||
* 3.3.2. [Initializing AlertManager](#InitializingAlertManager)
|
||||
* 3.3.3. [Key Configuration Fields](#KeyConfigurationFields)
|
||||
* 3.3.4. [Configuring SMTP Authentication Password](#ConfiguringSMTPAuthenticationPassword)
|
||||
* 3.3.5. [Useful Links for Common Email Servers](#UsefulLinksforCommonEmailServers)
|
||||
* 3.4. [Conclusion](#Conclusion)
|
||||
|
||||
<!-- vscode-markdown-toc-config
|
||||
numbering=true
|
||||
autoSave=true
|
||||
/vscode-markdown-toc-config -->
|
||||
<!-- /vscode-markdown-toc -->
|
||||
|
||||
OpenIM offers various flexible deployment options to suit different environments and requirements. Here is a simplified and optimized description of these deployment options:
|
||||
|
||||
1. Source Code Deployment:
|
||||
+ **Regular Source Code Deployment**: Deployment using the `nohup` method. This is a basic deployment method suitable for development and testing environments. For details, refer to the [Regular Source Code Deployment Guide](https://docs.openim.io/).
|
||||
+ **Production-Level Deployment**: Deployment using the `system` method, more suitable for production environments. This method provides higher stability and reliability. For details, refer to the [Production-Level Deployment Guide](https://docs.openim.io/guides/gettingStarted/install-openim-linux-system).
|
||||
2. Cluster Deployment:
|
||||
+ **Kubernetes Deployment**: Provides two deployment methods, including deployment through Helm and sealos. This is suitable for environments that require high availability and scalability. Specific methods can be found in the [Kubernetes Deployment Guide](https://docs.openim.io/guides/gettingStarted/k8s-deployment).
|
||||
3. Docker Deployment:
|
||||
+ **Regular Docker Deployment**: Suitable for quick deployments and small projects. For detailed information, refer to the [Docker Deployment Guide](https://docs.openim.io/guides/gettingStarted/dockerCompose).
|
||||
+ **Docker Compose Deployment**: Provides more convenient service management and configuration, suitable for complex multi-container applications.
|
||||
|
||||
Next, we will introduce the specific steps, monitoring, and management backend configuration for each of these deployment methods, as well as usage tips to help you choose the most suitable deployment option according to your needs.
|
||||
|
||||
## 1. <a name='SourceCodeDocker'></a>Source Code & Docker
|
||||
|
||||
### 1.1. <a name='Deployment'></a>Deployment
|
||||
|
||||
OpenIM deploys openim-server and openim-chat from source code, while other components are deployed via Docker.
|
||||
|
||||
For Docker deployment, you can deploy all components with a single command using the [openimsdk/openim-docker](https://github.com/openimsdk/openim-docker) repository. The deployment configuration can be found in the [environment.sh](https://github.com/openimsdk/open-im-server-deploy/blob/main/scripts/install/environment.sh) document, which provides information on how to learn and familiarize yourself with various environment variables.
|
||||
|
||||
For Prometheus, it is not enabled by default. To enable it, set the environment variable before executing `make init`:
|
||||
|
||||
```bash
|
||||
export PROMETHEUS_ENABLE=true # Default is false
|
||||
```
|
||||
|
||||
Then, execute:
|
||||
|
||||
```bash
|
||||
make init
|
||||
docker compose up -d
|
||||
```
|
||||
|
||||
### 1.2. <a name='Configuration'></a>Configuration
|
||||
|
||||
To configure Prometheus data sources in Grafana, follow these steps:
|
||||
|
||||
1. **Log in to Grafana**: First, open your web browser and access the Grafana URL. If you haven't changed the port, the address is typically [http://localhost:13000](http://localhost:13000/).
|
||||
|
||||
2. **Log in with default credentials**: Grafana's default username and password are both `admin`. You will be prompted to change the password on your first login.
|
||||
|
||||
3. **Access Data Sources Settings**:
|
||||
|
||||
+ In the left menu of Grafana, look for and click the "gear" icon representing "Configuration."
|
||||
+ In the configuration menu, select "Data Sources."
|
||||
|
||||
4. **Add a New Data Source**:
|
||||
|
||||
+ On the Data Sources page, click the "Add data source" button.
|
||||
+ In the list, find and select "Prometheus."
|
||||
|
||||
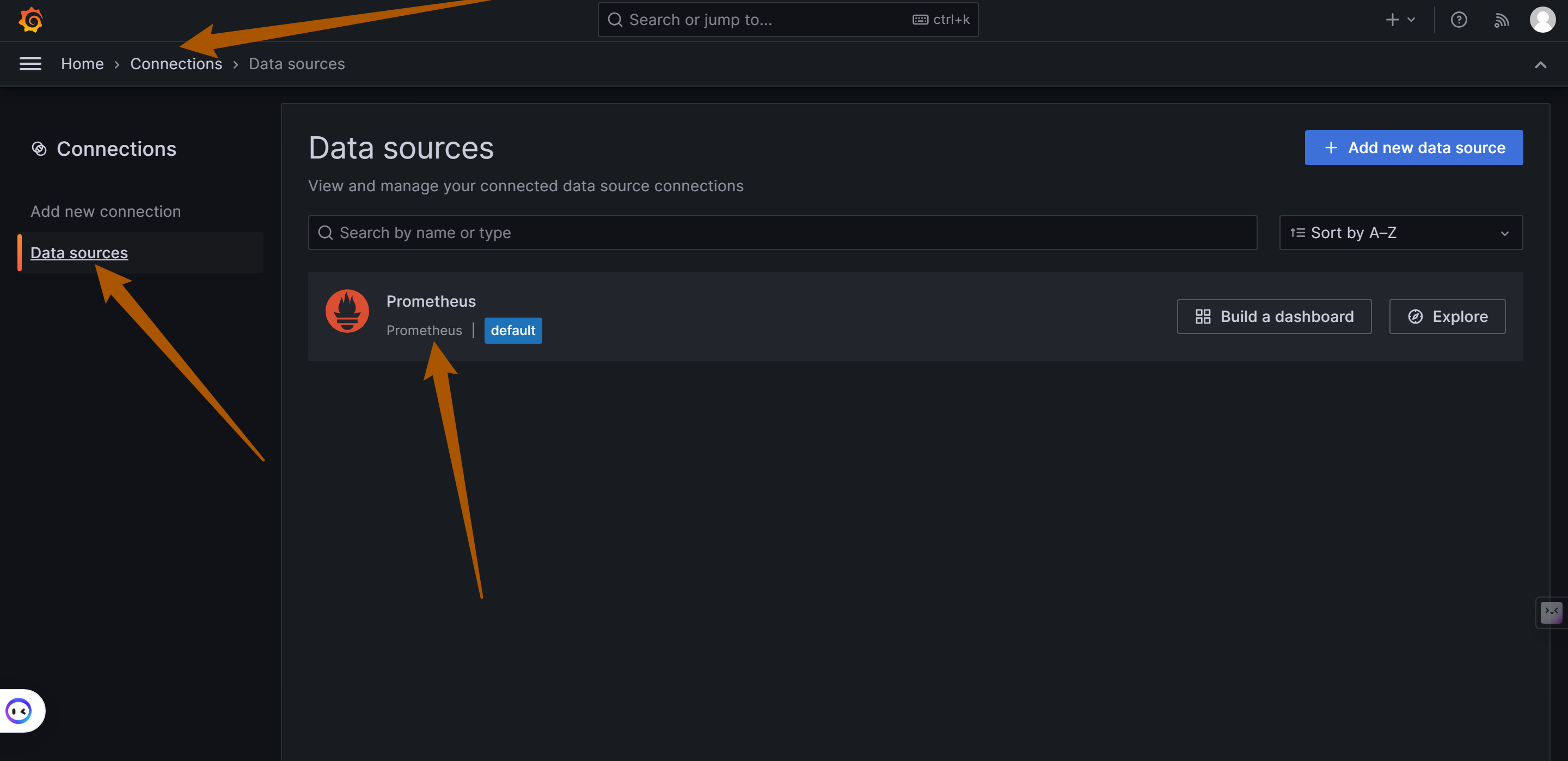
|
||||
|
||||
Click `Add New connection` to add more data sources, such as Loki (responsible for log storage and query processing).
|
||||
|
||||
5. **Configure the Prometheus Data Source**:
|
||||
|
||||
+ On the configuration page, fill in the details of the Prometheus server. This typically includes the URL of the Prometheus service (e.g., if Prometheus is running on the same machine as OpenIM, the URL might be `http://172.28.0.1:19090`, with the address matching the `DOCKER_BRIDGE_GATEWAY` variable address). OpenIM and the components are linked via a gateway. The default port used by OpenIM is `19090`.
|
||||
+ Adjust other settings as needed, such as authentication and TLS settings.
|
||||
|
||||
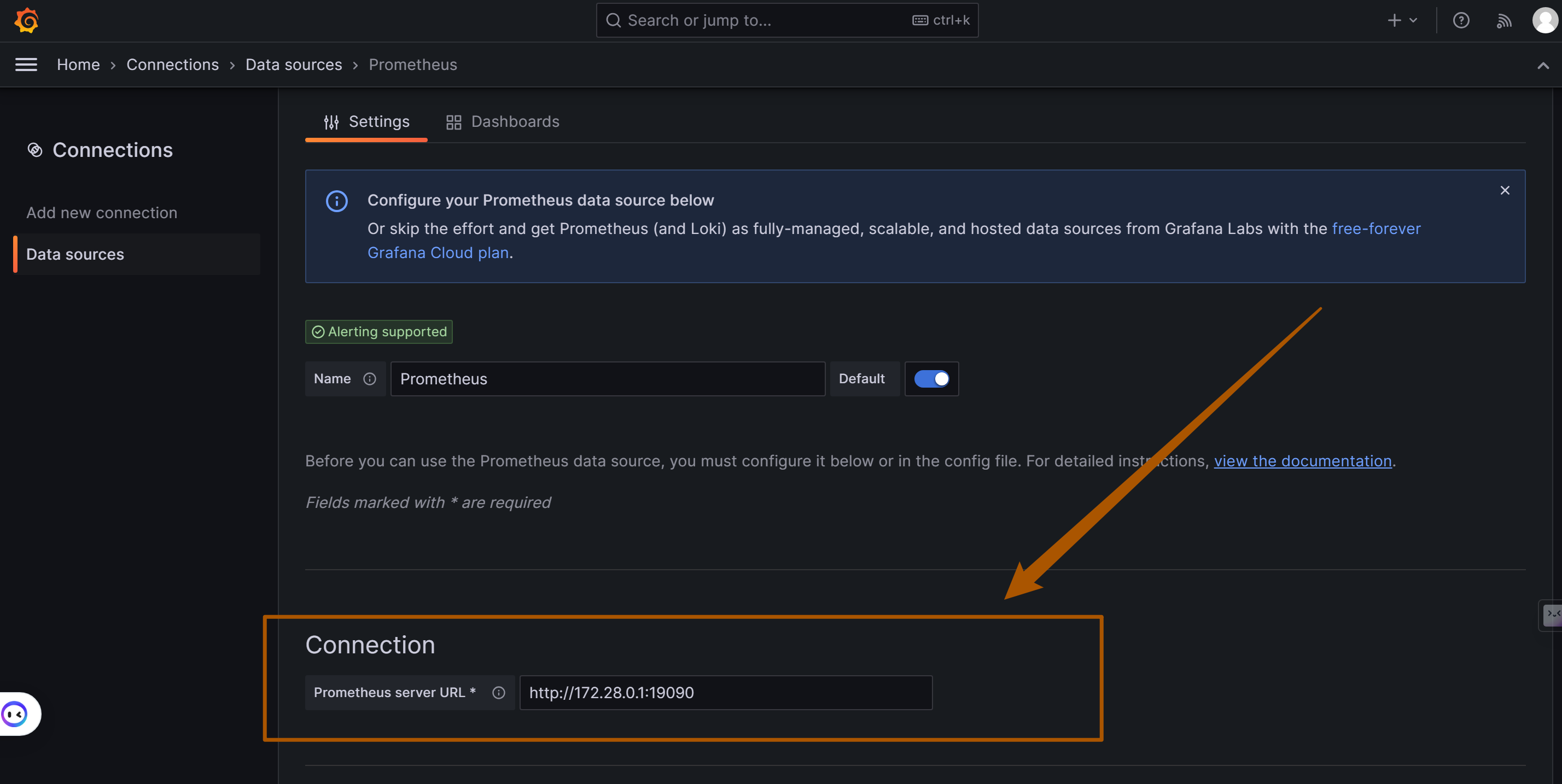
|
||||
|
||||
6. **Save and Test**:
|
||||
|
||||
+ After completing the configuration, click the "Save & Test" button to ensure that Grafana can successfully connect to Prometheus.
|
||||
|
||||
**Importing Dashboards in Grafana**
|
||||
|
||||
Importing Grafana Dashboards is a straightforward process and is applicable to OpenIM Server application services and Node Exporter. Here are detailed steps and necessary considerations:
|
||||
|
||||
**Key Metrics Overview and Deployment Steps**
|
||||
|
||||
To monitor OpenIM in Grafana, you need to focus on three categories of key metrics, each with its specific deployment and configuration steps:
|
||||
|
||||
**OpenIM Metrics (`prometheus-dashboard.yaml`)**:
|
||||
|
||||
- **Configuration File Path**: Find this at `config/prometheus-dashboard.yaml`.
|
||||
- **Enabling Monitoring**: Activate Prometheus monitoring by setting the environment variable: `export PROMETHEUS_ENABLE=true`.
|
||||
- **More Information**: For detailed instructions, see the [OpenIM Configuration Guide](https://docs.openim.io/configurations/prometheus-integration).
|
||||
|
||||
**Node Exporter**:
|
||||
|
||||
- **Container Deployment**: Use the container `quay.io/prometheus/node-exporter` for effective node monitoring.
|
||||
- **Access Dashboard**: Visit the [Node Exporter Full Feature Dashboard](https://grafana.com/grafana/dashboards/1860-node-exporter-full/) for dashboard integration either through YAML file download or ID.
|
||||
- **Deployment Guide**: For deployment steps, consult the [Node Exporter Deployment Documentation](https://prometheus.io/docs/guides/node-exporter/).
|
||||
|
||||
**Middleware Metrics**: Different middlewares require unique steps and configurations for monitoring:
|
||||
|
||||
- MySQL:
|
||||
- **Configuration**: Make sure MySQL is set up for performance monitoring.
|
||||
- **Guide**: See the [MySQL Monitoring Configuration Guide](https://grafana.com/docs/grafana/latest/datasources/mysql/).
|
||||
- Redis:
|
||||
- **Configuration**: Adjust Redis settings to enable monitoring data export.
|
||||
- **Guide**: Consult the [Redis Monitoring Guide](https://grafana.com/docs/grafana/latest/datasources/redis/).
|
||||
- MongoDB:
|
||||
- **Configuration**: Configure MongoDB for monitoring metrics.
|
||||
- **Guide**: Visit the [MongoDB Monitoring Guide](https://grafana.com/grafana/plugins/grafana-mongodb-datasource/).
|
||||
- Kafka:
|
||||
- **Configuration**: Set up Kafka for Prometheus monitoring integration.
|
||||
- **Guide**: Refer to the [Kafka Monitoring Guide](https://grafana.com/grafana/plugins/grafana-kafka-datasource/).
|
||||
- Zookeeper:
|
||||
- **Configuration**: Ensure Prometheus can monitor Zookeeper.
|
||||
- **Guide**: Check out the [Zookeeper Monitoring Configuration](https://grafana.com/docs/grafana/latest/datasources/zookeeper/).
|
||||
|
||||
**Importing Steps**:
|
||||
|
||||
1. Access the Dashboard Import Interface:
|
||||
|
||||
+ Click the `+` icon on the left menu or in the top right corner of Grafana, then select "Create."
|
||||
+ Choose "Import" to access the dashboard import interface.
|
||||
|
||||
2. **Perform Dashboard Import**:
|
||||
+ **Upload via File**: Directly upload your YAML file.
|
||||
+ **Paste Content**: Open the YAML file, copy its content, and paste it into the import interface.
|
||||
+ **Import via Grafana.com Dashboard**: Visit [Grafana Dashboards](https://grafana.com/grafana/dashboards/), search for the desired dashboard, and import it using its ID.
|
||||
3. **Configure the Dashboard**:
|
||||
+ Select the appropriate data source, such as the previously configured Prometheus.
|
||||
+ Adjust other settings, such as the dashboard name or folder.
|
||||
4. **Save and View the Dashboard**:
|
||||
+ After configuring, click "Import" to complete the process.
|
||||
+ Immediately view the new dashboard after successful import.
|
||||
|
||||
**Graph Examples:**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 1.3. <a name='MonitoringRunninginDockerGuide'></a>Monitoring Running in Docker Guide
|
||||
|
||||
#### 1.3.1. <a name='Introduction'></a>Introduction
|
||||
|
||||
This guide provides the steps to run OpenIM using Docker. OpenIM is an open-source instant messaging solution that can be quickly deployed using Docker. For more information, please refer to the [OpenIM Docker GitHub](https://github.com/openimsdk/openim-docker).
|
||||
|
||||
#### 1.3.2. <a name='Prerequisites'></a>Prerequisites
|
||||
|
||||
+ Ensure that Docker and Docker Compose are installed.
|
||||
+ Basic understanding of Docker and containerization technology.
|
||||
|
||||
#### 1.3.3. <a name='Step1:ClonetheRepository'></a>Step 1: Clone the Repository
|
||||
|
||||
First, clone the OpenIM Docker repository:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/openimsdk/openim-docker.git
|
||||
```
|
||||
|
||||
Navigate to the repository directory and check the `README` file for more information and configuration options.
|
||||
|
||||
#### 1.3.4. <a name='Step2:StartDockerCompose'></a>Step 2: Start Docker Compose
|
||||
|
||||
In the repository directory, run the following command to start the service:
|
||||
|
||||
```bash
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
This will download the required Docker images and start the OpenIM service.
|
||||
|
||||
#### 1.3.5. <a name='Step3:UsetheOpenIMWebInterface'></a>Step 3: Use the OpenIM Web Interface
|
||||
|
||||
+ Open a browser in private mode and access [OpenIM Web](http://localhost:11001/).
|
||||
+ Register two users and try adding friends.
|
||||
+ Test sending messages and pictures.
|
||||
|
||||
#### 1.3.6. <a name='RunningEffect'></a>Running Effect
|
||||
|
||||
|
||||
|
||||
#### 1.3.7. <a name='Step4:AccesstheAdminPanel'></a>Step 4: Access the Admin Panel
|
||||
|
||||
+ Access the [OpenIM Admin Panel](http://localhost:11002/).
|
||||
+ Log in using the default username and password (`admin1:admin1`).
|
||||
|
||||
Running Effect Image:
|
||||
|
||||
|
||||
|
||||
#### 1.3.8. <a name='Step5:AccesstheMonitoringInterface'></a>Step 5: Access the Monitoring Interface
|
||||
|
||||
+ Log in to the [Monitoring Interface](http://localhost:3000/login) using the credentials (`admin:admin`).
|
||||
|
||||
#### 1.3.9. <a name='NextSteps'></a>Next Steps
|
||||
|
||||
+ Configure and manage the services following the steps provided in the OpenIM source code.
|
||||
+ Refer to the `README` file for advanced configuration and management.
|
||||
|
||||
#### 1.3.10. <a name='Troubleshooting'></a>Troubleshooting
|
||||
|
||||
+ If you encounter any issues, please check the documentation on [OpenIM Docker GitHub](https://github.com/openimsdk/openim-docker) or search for related issues in the Issues section.
|
||||
+ If the problem persists, you can create an issue on the [openim-docker](https://github.com/openimsdk/openim-docker/issues/new/choose) repository or the [openim-server](https://github.com/openimsdk/open-im-server-deploy/issues/new/choose) repository.
|
||||
|
||||
|
||||
|
||||
## 2. <a name='Kubernetes'></a>Kubernetes
|
||||
|
||||
Refer to [openimsdk/helm-charts](https://github.com/openimsdk/helm-charts).
|
||||
|
||||
When deploying and monitoring OpenIM in a Kubernetes environment, you will focus on three main metrics: middleware, custom OpenIM metrics, and Node Exporter. Here are detailed steps and guidelines:
|
||||
|
||||
### 2.1. <a name='MiddlewareMonitoring'></a>Middleware Monitoring
|
||||
|
||||
Middleware monitoring is crucial to ensure the overall system's stability. Typically, this includes monitoring the following components:
|
||||
|
||||
+ **MySQL**: Monitor database performance, query latency, and more.
|
||||
+ **Redis**: Track operation latency, memory usage, and more.
|
||||
+ **MongoDB**: Observe database operations, resource usage, and more.
|
||||
+ **Kafka**: Monitor message throughput, latency, and more.
|
||||
+ **Zookeeper**: Keep an eye on cluster status, performance metrics, and more.
|
||||
|
||||
For Kubernetes environments, you can use the corresponding Prometheus Exporters to collect monitoring data for these middleware components.
|
||||
|
||||
### 2.2. <a name='CustomOpenIMMetrics'></a>Custom OpenIM Metrics
|
||||
|
||||
Custom OpenIM metrics provide essential information about the OpenIM application itself, such as user activity, message traffic, system performance, and more. To monitor these metrics in Kubernetes:
|
||||
|
||||
+ Ensure OpenIM application configurations expose Prometheus metrics.
|
||||
+ When deploying using Helm charts (refer to [OpenIM Helm Charts](https://github.com/openimsdk/helm-charts)), pay attention to configuring relevant monitoring settings.
|
||||
|
||||
### 2.3. <a name='NodeExporter'></a>Node Exporter
|
||||
|
||||
Node Exporter is used to collect hardware and operating system-level metrics for Kubernetes nodes, such as CPU, memory, disk usage, and more. To integrate Node Exporter in Kubernetes:
|
||||
|
||||
+ Deploy Node Exporter using the appropriate Helm chart. You can find information and guides on [Prometheus Community](https://prometheus.io/docs/guides/node-exporter/).
|
||||
+ Ensure Node Exporter's data is collected by Prometheus instances within your cluster.
|
||||
|
||||
|
||||
|
||||
## 3. <a name='SettingUpandConfiguringAlertManagerUsingEnvironmentVariablesandmakeinit'></a>Setting Up and Configuring AlertManager Using Environment Variables and `make init`
|
||||
|
||||
### 3.1. <a name='Introduction-1'></a>Introduction
|
||||
|
||||
AlertManager, a component of the Prometheus monitoring system, handles alerts sent by client applications such as the Prometheus server. It takes care of deduplicating, grouping, and routing them to the correct receiver. This document outlines how to set up and configure AlertManager using environment variables and the `make init` command. We will focus on configuring key fields like the sender's email, SMTP settings, and SMTP authentication password.
|
||||
|
||||
### 3.2. <a name='Prerequisites-1'></a>Prerequisites
|
||||
|
||||
+ Basic knowledge of terminal and command-line operations.
|
||||
+ AlertManager installed on your system.
|
||||
+ Access to an SMTP server for sending emails.
|
||||
|
||||
### 3.3. <a name='ConfigurationSteps'></a>Configuration Steps
|
||||
|
||||
#### 3.3.1. <a name='ExportingEnvironmentVariables'></a>Exporting Environment Variables
|
||||
|
||||
Before initializing AlertManager, you need to set environment variables. These variables are used to configure the AlertManager settings without altering the code. Use the `export` command in your terminal. Here are some key variables you might set:
|
||||
|
||||
+ `export ALERTMANAGER_RESOLVE_TIMEOUT='5m'`
|
||||
+ `export ALERTMANAGER_SMTP_FROM='alert@example.com'`
|
||||
+ `export ALERTMANAGER_SMTP_SMARTHOST='smtp.example.com:465'`
|
||||
+ `export ALERTMANAGER_SMTP_AUTH_USERNAME='alert@example.com'`
|
||||
+ `export ALERTMANAGER_SMTP_AUTH_PASSWORD='your_password'`
|
||||
+ `export ALERTMANAGER_SMTP_REQUIRE_TLS='false'`
|
||||
|
||||
#### 3.3.2. <a name='InitializingAlertManager'></a>Initializing AlertManager
|
||||
|
||||
After setting the necessary environment variables, you can initialize AlertManager by running the `make init` command. This command typically runs a script that prepares AlertManager with the provided configuration.
|
||||
|
||||
#### 3.3.3. <a name='KeyConfigurationFields'></a>Key Configuration Fields
|
||||
|
||||
##### a. Sender's Email (`ALERTMANAGER_SMTP_FROM`)
|
||||
|
||||
This variable sets the email address that will appear as the sender in the notifications sent by AlertManager.
|
||||
|
||||
##### b. SMTP Configuration
|
||||
|
||||
+ **SMTP Server (`ALERTMANAGER_SMTP_SMARTHOST`):** Specifies the address and port of the SMTP server used for sending emails.
|
||||
+ **SMTP Authentication Username (`ALERTMANAGER_SMTP_AUTH_USERNAME`):** The username for authenticating with the SMTP server.
|
||||
+ **SMTP Authentication Password (`ALERTMANAGER_SMTP_AUTH_PASSWORD`):** The password for SMTP server authentication. It's crucial to keep this value secure.
|
||||
|
||||
#### 3.3.4. <a name='ConfiguringSMTPAuthenticationPassword'></a>Configuring SMTP Authentication Password
|
||||
|
||||
The SMTP authentication password can be set using the `ALERTMANAGER_SMTP_AUTH_PASSWORD` environment variable. It's recommended to use a secure method to set this variable to avoid exposing sensitive information. For instance, you might read the password from a secure file or a secret management tool.
|
||||
|
||||
#### 3.3.5. <a name='UsefulLinksforCommonEmailServers'></a>Useful Links for Common Email Servers
|
||||
|
||||
For specific configurations related to common email servers, you may refer to their respective documentation:
|
||||
|
||||
+ Gmail SMTP Settings:
|
||||
+ [Gmail SMTP Configuration](https://support.google.com/mail/answer/7126229?hl=en)
|
||||
+ Microsoft Outlook SMTP Settings:
|
||||
+ [Outlook Email Settings](https://support.microsoft.com/en-us/office/pop-imap-and-smtp-settings-8361e398-8af4-4e97-b147-6c6c4ac95353)
|
||||
+ Yahoo Mail SMTP Settings:
|
||||
+ [Yahoo SMTP Configuration](https://help.yahoo.com/kb/SLN4724.html)
|
||||
|
||||
### 3.4. <a name='Conclusion'></a>Conclusion
|
||||
|
||||
Setting up and configuring AlertManager with environment variables provides a flexible and secure way to manage alert settings. By following the above steps, you can easily configure AlertManager for your monitoring needs. Always ensure to secure sensitive information, especially when dealing with SMTP authentication credentials.
|
||||
60
docs/contrib/protoc-tools.md
Normal file
60
docs/contrib/protoc-tools.md
Normal file
@@ -0,0 +1,60 @@
|
||||
# OpenIM Protoc Tool
|
||||
|
||||
## Introduction
|
||||
|
||||
OpenIM is passionate about ensuring that its suite of tools is custom-tailored to cater to the unique needs of its users. That commitment led us to develop and release our custom Protoc tool, version v1.0.0.
|
||||
|
||||
### Why a Custom Version?
|
||||
|
||||
There are several reasons to choose our custom Protoc tool over generic open-source versions:
|
||||
|
||||
- **Specialized Features**: OpenIM's Protoc tool has been enriched with features and plugins that are optimized for the OpenIM ecosystem. This makes it more aligned with the needs of OpenIM users.
|
||||
- **Optimized Performance**: Built from the ground up with OpenIM's infrastructure in mind, our tool guarantees faster and more efficient operations.
|
||||
- **Enhanced Compatibility**: Our Protoc tool ensures full compatibility with OpenIM's offerings, minimizing potential conflicts and integration challenges.
|
||||
- **Rich Output Support**: Unlike generic tools, our custom tool provides a wide array of output options including C++, C#, Java, Kotlin, Objective-C, PHP, Python, Ruby, and more. This allows developers to generate code for their preferred platform with ease.
|
||||
|
||||
## Download
|
||||
|
||||
+ https://github.com/OpenIMSDK/Open-IM-Protoc
|
||||
|
||||
Access the official release of the Protoc tool on the OpenIM repository here: [OpenIM Protoc Tool v1.0.0 Release](https://github.com/OpenIMSDK/Open-IM-Protoc/releases/tag/v1.0.0)
|
||||
|
||||
### Direct Download Links:
|
||||
|
||||
- **Windows**: [Download for Windows](https://github.com/OpenIMSDK/Open-IM-Protoc/releases/download/v1.0.0/windows.zip)
|
||||
- **Linux**: [Download for Linux](https://github.com/OpenIMSDK/Open-IM-Protoc/releases/download/v1.0.0/linux.zip)
|
||||
|
||||
## Installation
|
||||
|
||||
For Windows:
|
||||
|
||||
1. Navigate to the Windows download link provided above and download the version suitable for your system.
|
||||
2. Extract the contents of the zip file.
|
||||
3. Add the path of the extracted tool to your `PATH` environment variable to run the Protoc tool directly from the command line.
|
||||
|
||||
For Linux:
|
||||
|
||||
1. Navigate to the Linux download link provided above and download the version suitable for your system.
|
||||
2. Extract the contents of the zip file.
|
||||
3. Use `chmod +x ./*` to make the extracted files executable.
|
||||
4. Add the path of the extracted tool to your `PATH` environment variable to run the Protoc tool directly from the command line.
|
||||
|
||||
## Usage
|
||||
|
||||
The OpenIM Protoc tool provides a multitude of options for parsing `.proto` files and generating output:
|
||||
|
||||
```
|
||||
|
||||
./protoc [OPTION] PROTO_FILES
|
||||
```
|
||||
|
||||
Some of the key options include:
|
||||
|
||||
- `--proto_path=PATH`: Specify the directory to search for imports.
|
||||
- `--version`: Show version info.
|
||||
- `--encode=MESSAGE_TYPE`: Convert a text-format message of a given type from standard input to binary on standard output.
|
||||
- `--decode=MESSAGE_TYPE`: Convert a binary message of a given type from standard input to text format on standard output.
|
||||
- `--cpp_out=OUT_DIR`: Generate C++ header and source.
|
||||
- `--java_out=OUT_DIR`: Generate Java source file.
|
||||
|
||||
... and many more. For a full list of options, run `./protoc --help` or refer to the official documentation.
|
||||
251
docs/contrib/release.md
Normal file
251
docs/contrib/release.md
Normal file
@@ -0,0 +1,251 @@
|
||||
# OpenIM Release Automation Design Document
|
||||
|
||||
This document outlines the automation process for releasing OpenIM. You can use the `make release` command for automated publishing. We will discuss how to use the `make release` command and Github Actions CICD separately, while also providing insight into the design principles involved.
|
||||
|
||||
## Github Actions Automation
|
||||
|
||||
In our CICD pipeline, we have implemented logic for automating the release process using the goreleaser tool. To achieve this, follow these steps on your local machine or server:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/openimsdk/open-im-server-deploy
|
||||
cd open-im-server-deploy
|
||||
git tag -a v3.6.0 -s -m "release: xxx"
|
||||
# For pre-release versions: git tag -a v3.6.0-rc.0 -s -m "pre-release: xxx"
|
||||
git push origin v3.6.0
|
||||
```
|
||||
|
||||
The remaining tasks are handled by automated processes:
|
||||
|
||||
+ Automatically complete the release publication on Github
|
||||
+ Automatically build the `v3.6.0` version image and push it to aliyun, dockerhub, and github
|
||||
|
||||
Through these automated steps, we achieve rapid and efficient OpenIM version releases, simplifying the release process and enhancing productivity.
|
||||
|
||||
|
||||
Certainly, here is the continuation of the document in English:
|
||||
|
||||
## Local Make Release Design
|
||||
|
||||
There are two primary scenarios for local usage:
|
||||
|
||||
+ Advanced compilation and release, manually executed locally
|
||||
+ Quick compilation verification and version release, manually executed locally
|
||||
|
||||
**These two scenarios can also be combined, for example, by tagging locally and then releasing:**
|
||||
|
||||
```bash
|
||||
git add .
|
||||
git commit -a -s -m "release(v3.6.0): ......"
|
||||
git tag v3.6.0
|
||||
git release
|
||||
git push origin main
|
||||
```
|
||||
|
||||
In a local environment, you can use the `make release` command to complete the release process. The main implementation logic can be found in the `/data/workspaces/open-im-server-deploy/scripts/lib/release.sh` file. First, let's explore its usage through the help information.
|
||||
|
||||
### Help Information
|
||||
|
||||
To view the help information, execute the following command:
|
||||
|
||||
```bash
|
||||
$ ./scripts/release.sh --help
|
||||
Usage: release.sh [options]
|
||||
Options:
|
||||
-h, --help Display this help message
|
||||
-se, --setup-env Execute environment setup
|
||||
-vp, --verify-prereqs Execute prerequisite verification
|
||||
-bc, --build-command Execute build command
|
||||
-bi, --build-image Execute build image (default is not executed)
|
||||
-pt, --package-tarballs Execute tarball packaging
|
||||
-ut, --upload-tarballs Execute tarball upload
|
||||
-gr, --github-release Execute GitHub release
|
||||
-gc, --generate-changelog Execute changelog generation
|
||||
```
|
||||
|
||||
### Default Behavior
|
||||
|
||||
If no options are provided, all operations are executed by default:
|
||||
|
||||
```bash
|
||||
# If no options are provided, enable all operations by default
|
||||
if [ "$#" -eq 0 ]; then
|
||||
perform_setup_env=true
|
||||
perform_verify_prereqs=true
|
||||
perform_build_command=true
|
||||
perform_package_tarballs=true
|
||||
perform_upload_tarballs=true
|
||||
perform_github_release=true
|
||||
perform_generate_changelog=true
|
||||
# TODO: Defaultly not enable build_image
|
||||
# perform_build_image=true
|
||||
fi
|
||||
```
|
||||
|
||||
### Environment Variable Setup
|
||||
|
||||
Before starting, you need to set environment variables:
|
||||
|
||||
```bash
|
||||
export TENCENT_SECRET_KEY=OZZ****************************
|
||||
export TENCENT_SECRET_ID=AKI****************************
|
||||
```
|
||||
|
||||
### Modifying COS Account and Password
|
||||
|
||||
If you need to change the COS account, password, and bucket information, please modify the following section in the `/data/workspaces/open-im-server-deploy/scripts/lib/release.sh` file:
|
||||
|
||||
```bash
|
||||
readonly BUCKET="openim-1306374445"
|
||||
readonly REGION="ap-guangzhou"
|
||||
readonly COS_RELEASE_DIR="openim-release"
|
||||
```
|
||||
|
||||
### GitHub Release Configuration
|
||||
|
||||
If you intend to use the GitHub Release feature, you also need to set the environment variable:
|
||||
|
||||
```bash
|
||||
export GITHUB_TOKEN="your_github_token"
|
||||
```
|
||||
|
||||
### Modifying GitHub Release Basic Information
|
||||
|
||||
If you need to modify the basic information of GitHub Release, please edit the following section in the `/data/workspaces/open-im-server-deploy/scripts/lib/release.sh` file:
|
||||
|
||||
```bash
|
||||
# OpenIM GitHub account information
|
||||
readonly OPENIM_GITHUB_ORG=openimsdk
|
||||
readonly OPENIM_GITHUB_REPO=open-im-server-deploy
|
||||
```
|
||||
|
||||
This setup allows you to configure and execute the local release process according to your specific needs.
|
||||
|
||||
|
||||
### GitHub Release Versioning Rules
|
||||
|
||||
Firstly, it's important to note that GitHub Releases should primarily be for pre-release versions. However, goreleaser might provide a `prerelease: auto` option, which automatically marks versions with pre-release indicators like `-rc1`, `-beta`, etc., as pre-releases.
|
||||
|
||||
So, if your most recent tag does not have pre-release indicators such as `-rc1` or `-beta`, even if you use `make release` for pre-release versions, goreleaser might still consider them as formal releases.
|
||||
|
||||
To avoid this issue, I have added the `--draft` flag to github-release. This way, all releases are created as drafts.
|
||||
|
||||
## CICD Release Documentation Design
|
||||
|
||||
The release records still require manual composition for GitHub Release. This is different from github-release.
|
||||
|
||||
This approach ensures that all releases are initially created as drafts, allowing you to manually review and edit the release documentation on GitHub. This manual step provides more control and allows you to curate release notes and other information before making them public.
|
||||
|
||||
|
||||
## Makefile Section
|
||||
|
||||
This document aims to elaborate and explain key sections of the OpenIM Release automation design, including the Makefile section and functions within the code. Below, we will provide a detailed explanation of the logic and functions of each section.
|
||||
|
||||
In the project's root directory, the Makefile imports a subdirectory:
|
||||
|
||||
```makefile
|
||||
include scripts/make-rules/release.mk
|
||||
```
|
||||
|
||||
And defines the `release` target as follows:
|
||||
|
||||
```makefile
|
||||
## release: release the project ✨
|
||||
.PHONY: release release: release.verify release.ensure-tag
|
||||
@scripts/release.sh
|
||||
```
|
||||
|
||||
### Importing Subdirectory
|
||||
|
||||
At the beginning of the Makefile, the `include scripts/make-rules/release.mk` statement imports the `release.mk` file from the subdirectory. This file contains rules and configurations related to releases to be used in subsequent operations.
|
||||
|
||||
### The `release` Target
|
||||
|
||||
The Makefile defines a target named `release`, which is used to execute the project's release operation. This target is marked as a phony target (`.PHONY`), meaning it doesn't represent an actual file or directory but serves as an identifier for executing a series of actions.
|
||||
|
||||
In the `release` target, two dependency targets are executed first: `release.verify` and `release.ensure-tag`. Afterward, the `scripts/release.sh` script is called to perform the actual release operation.
|
||||
|
||||
## Logic of `release.verify` and `release.ensure-tag`
|
||||
|
||||
```makefile
|
||||
## release.verify: Check if a tool is installed and install it
|
||||
.PHONY: release.verify
|
||||
release.verify: tools.verify.git-chglog tools.verify.github-release tools.verify.coscmd tools.verify.coscli
|
||||
|
||||
## release.ensure-tag: ensure tag
|
||||
.PHONY: release.ensure-tag
|
||||
release.ensure-tag: tools.verify.gsemver
|
||||
@scripts/ensure-tag.sh
|
||||
```
|
||||
|
||||
### `release.verify` Target
|
||||
|
||||
The `release.verify` target is used to check and install tools. It depends on four sub-targets: `tools.verify.git-chglog`, `tools.verify.github-release`, `tools.verify.coscmd`, and `tools.verify.coscli`. These sub-targets aim to check if specific tools are installed and attempt to install them if they are not.
|
||||
|
||||
The purpose of this target is to ensure that the necessary tools required for the release process are available so that subsequent operations can be executed smoothly.
|
||||
|
||||
### `release.ensure-tag` Target
|
||||
|
||||
The `release.ensure-tag` target is used to ensure that the project has a version tag. It depends on the sub-target `tools.verify.gsemver`, indicating that it should check if the `gsemver` tool is installed before executing.
|
||||
|
||||
When the `release.ensure-tag` target is executed, it calls the `scripts/ensure-tag.sh` script to ensure that the project has a version tag. Version tags are typically used to identify specific versions of the project for management and release in version control systems.
|
||||
|
||||
## Logic of `release.sh` Script
|
||||
|
||||
```bash
|
||||
openim::golang::setup_env
|
||||
openim::build::verify_prereqs
|
||||
openim::release::verify_prereqs
|
||||
#openim::build::build_image
|
||||
openim::build::build_command
|
||||
openim::release::package_tarballs
|
||||
openim::release::upload_tarballs
|
||||
git push origin ${VERSION}
|
||||
#openim::release::github_release
|
||||
#openim::release::generate_changelog
|
||||
```
|
||||
|
||||
The `release.sh` script is responsible for executing the actual release operations. Below is the logic of this script:
|
||||
|
||||
1. `openim::golang::setup_env`: This function sets up some configurations for the Golang development environment.
|
||||
|
||||
2. `openim::build::verify_prereqs`: This function is used to verify whether the prerequisites for building are met. This includes checking dependencies, environment variables, and more.
|
||||
|
||||
3. `openim::release::verify_prereqs`: Similar to the previous function, this one is used to verify whether the prerequisites for the release are met. It focuses on conditions relevant to the release.
|
||||
|
||||
4. `openim::build::build_command`: This function is responsible for building the project's command, which typically involves compiling the project or performing other build operations.
|
||||
|
||||
5. `openim::release::package_tarballs`: This function is used to package tarball files required for the release. These tarballs are usually used for distribution packages during the release.
|
||||
|
||||
6. `openim::release::upload_tarballs`: This function is used to upload the packaged tarball files, typically to a distribution platform or repository.
|
||||
|
||||
7. `git push origin ${VERSION}`: This line of command pushes the version tag to the remote Git repository's `origin` branch, marking this release in the version control system.
|
||||
|
||||
In the comments, you can see that there are some operations that are commented out, such as `openim::build::build_image`, `openim::release::github_release`, and `openim::release::generate_changelog`. These operations are related to building images, releasing to GitHub, and generating changelogs, and they can be enabled in the release process as needed.
|
||||
|
||||
Let's take a closer look at the function responsible for packaging the tarball files:
|
||||
|
||||
```bash
|
||||
function openim::release::package_tarballs() {
|
||||
# Clean out any old releases
|
||||
rm -rf "${RELEASE_STAGE}" "${RELEASE_TARS}" "${RELEASE_IMAGES}"
|
||||
mkdir -p "${RELEASE_TARS}"
|
||||
openim::release::package_src_tarball &
|
||||
openim::release::package_client_tarballs &
|
||||
openim::release::package_openim_manifests_tarball &
|
||||
openim::release::package_server_tarballs &
|
||||
openim::util::wait-for-jobs || { openim::log::error "previous tarball phase failed"; return 1; }
|
||||
|
||||
openim::release::package_final_tarball & # _final depends on some of the previous phases
|
||||
openim::util::wait-for-jobs || { openim::log::error "previous tarball phase failed"; return 1; }
|
||||
}
|
||||
```
|
||||
|
||||
The `openim::release::package_tarballs()` function is responsible for packaging the tarball files required for the release. Here is the specific logic of this function:
|
||||
|
||||
1. `rm -rf "${RELEASE_STAGE}" "${RELEASE_TARS}" "${RELEASE_IMAGES}"`: First, the function removes any old release directories and files to ensure a clean starting state.
|
||||
|
||||
2. `mkdir -p "${RELEASE_TARS}"`: Next, it creates a directory `${RELEASE_TARS}` to store the packaged tarball files. If the directory doesn't exist, it will be created.
|
||||
|
||||
3. `openim::release::package_final_tarball &`: This is an asynchronous operation that depends on some of the previous phases. It is likely used to package the final tarball file, which includes the contents of all previous asynchronous operations.
|
||||
|
||||
4. `openim::util::wait-for-jobs`: It waits for all asynchronous operations to complete. If any of the previous asynchronous operations fail, an error will be returned.
|
||||
263
docs/contrib/test.md
Normal file
263
docs/contrib/test.md
Normal file
@@ -0,0 +1,263 @@
|
||||
# OpenIM RPC Service Test Control Script Documentation
|
||||
|
||||
This document serves as a comprehensive guide to understanding and utilizing the `test.sh` script for testing OpenIM RPC services. The `test.sh` script is a collection of bash functions designed to test various aspects of the OpenIM RPC services, ensuring that each part of the API is functioning as expected.
|
||||
|
||||
+ Scripts:https://github.com/openimsdk/open-im-server-deploy/tree/main/scripts/install/test.sh
|
||||
|
||||
For some complex, bulky functional tests, performance tests, and various e2e tests, We are all in the current warehouse to https://github.com/openimsdk/open-im-server-deploy/tree/main/test or https://github.com/openim-sigs/test-infra directory In the.
|
||||
|
||||
+ About OpenIM Feature [Test Docs](https://docs.google.com/spreadsheets/d/1zELWkwxgOOZ7u5pmYCqqaFnvZy2SVajv/edit?usp=sharing&ouid=103266350914914783293&rtpof=true&sd=true)
|
||||
|
||||
## Util Test
|
||||
|
||||
Let's restructure and enhance the document under a unified second-level heading, adding clarity and details for better comprehension and visual appeal.
|
||||
|
||||
---
|
||||
|
||||
## Development Guide
|
||||
|
||||
### Comprehensive Testing Instructions
|
||||
|
||||
#### Running Unit Tests
|
||||
|
||||
- **Command**: To execute unit tests, input the following in your terminal:
|
||||
```
|
||||
make test
|
||||
```
|
||||
|
||||
#### Evaluating Test Coverage
|
||||
|
||||
- **Overview**: It's crucial to assess how much of your code is covered by tests.
|
||||
- **Command**:
|
||||
```bash
|
||||
make cover
|
||||
```
|
||||
This command generates a report detailing the percentage of your code tested, ensuring adherence to quality standards.
|
||||
|
||||
#### Conducting API Tests
|
||||
|
||||
- **Purpose**: API tests validate the interaction and functionality of your application's interfaces.
|
||||
- **How to Run**:
|
||||
```
|
||||
make test-api
|
||||
```
|
||||
Use this to check the integrity and reliability of your API endpoints.
|
||||
|
||||
#### End-to-End (E2E) Testing
|
||||
|
||||
- **Scope**: E2E tests simulate real-user scenarios from start to finish.
|
||||
- **Execution**:
|
||||
```
|
||||
make test-e2e
|
||||
```
|
||||
This comprehensive testing ensures your application performs as expected in real-world situations.
|
||||
|
||||
### Crafting Unit Test Cases
|
||||
|
||||
#### Setup for Test Case Generation
|
||||
|
||||
- **Installation**: Install the `gotests` tool to generate test cases automatically.
|
||||
```bash
|
||||
make install.gotests
|
||||
```
|
||||
This command installs the `gotests` tool for test case generation.
|
||||
|
||||
- **Environment Preparation**: Define your test template environment variable and generate test cases as shown below:
|
||||
```bash
|
||||
export GOTESTS_TEMPLATE=testify
|
||||
gotests -i -w -only keyFunc .
|
||||
```
|
||||
This prepares your environment for test case generation using the `testify` template.
|
||||
|
||||
#### Isolating Function Tests
|
||||
|
||||
- **Single Function Testing**: When you need to focus on testing a single function for detailed examination.
|
||||
- **Method**:
|
||||
```bash
|
||||
go test -v -run TestKeyFunc
|
||||
```
|
||||
This command specifically runs tests for `TestKeyFunc`, allowing targeted debugging and validation.
|
||||
|
||||
### Important Note
|
||||
|
||||
- **Quality Assurance**: Throughout your development process, it is imperative to ensure that the unit test coverage meets or surpasses the standards set by OpenIM.
|
||||
- **Maintaining Standards**: Regularly running your tests with
|
||||
```make test```
|
||||
supports maintaining high code quality and adherence to OpenIM's rigorous testing benchmarks.
|
||||
|
||||
## E2E Test
|
||||
|
||||
TODO
|
||||
|
||||
## Api Test
|
||||
|
||||
The `test.sh` script is located within the `./scripts/install/` directory of the OpenIM service's codebase. To use the script, navigate to this directory from your terminal:
|
||||
|
||||
```bash
|
||||
cd ./scripts/install/
|
||||
chmod +x test.sh
|
||||
```
|
||||
|
||||
### Running the Entire Test Suite
|
||||
|
||||
To execute all available tests, you can either call the script directly or use the `make` command:
|
||||
|
||||
```
|
||||
./test.sh openim::test::test
|
||||
```
|
||||
|
||||
Or, if you have a `Makefile` that defines the `test-api` target:
|
||||
|
||||
```bash
|
||||
make test-api
|
||||
```
|
||||
|
||||
Alternatively, you can invoke specific test functions by passing them as arguments:
|
||||
|
||||
```
|
||||
./test.sh openim::test::<function_name>
|
||||
```
|
||||
|
||||
This `make` command should be equivalent to running `./test.sh openim::test::test`, provided that the `Makefile` is configured accordingly.
|
||||
|
||||
|
||||
|
||||
### Executing Individual Test Functions
|
||||
|
||||
If you wish to run a specific set of tests, you can call the relevant function by passing it as an argument to the script. Here are some examples:
|
||||
|
||||
**Message Tests:**
|
||||
|
||||
```bash
|
||||
./test.sh openim::test::msg
|
||||
```
|
||||
|
||||
**Authentication Tests:**
|
||||
|
||||
```bash
|
||||
./test.sh openim::test::auth
|
||||
```
|
||||
|
||||
**User Tests:**
|
||||
|
||||
```bash
|
||||
./test.sh openim::test::user
|
||||
```
|
||||
|
||||
**Friend Tests:**
|
||||
|
||||
```bash
|
||||
./test.sh openim::test::friend
|
||||
```
|
||||
|
||||
**Group Tests:**
|
||||
|
||||
```bash
|
||||
./test.sh openim::test::group
|
||||
```
|
||||
|
||||
Each of these commands will run the test suite associated with the specific functionality of the OpenIM service.
|
||||
|
||||
|
||||
|
||||
### Detailed Function Test Examples
|
||||
|
||||
T**esting Message Sending and Receiving:**
|
||||
|
||||
To test message functionality, the `openim::test::msg` function is called. It will register a user, send a message, and clear messages to ensure that the messaging service is operational.
|
||||
|
||||
```bash
|
||||
./test.sh openim::test::msg
|
||||
```
|
||||
|
||||
**Testing User Registration and Account Checks:**
|
||||
|
||||
The `openim::test::user` function will create new user accounts and perform a series of checks on these accounts to verify that user registration and account queries are functioning properly.
|
||||
|
||||
```bash
|
||||
./test.sh openim::test::user
|
||||
```
|
||||
|
||||
**Testing Friend Management:**
|
||||
|
||||
By invoking `openim::test::friend`, the script will test adding friends, checking friendship status, managing friend requests, and handling blacklisting.
|
||||
|
||||
```bash
|
||||
./test.sh openim::test::friend
|
||||
```
|
||||
|
||||
**Testing Group Operations:**
|
||||
|
||||
The `openim::test::group` function tests group creation, member addition, information retrieval, and member management within groups.
|
||||
|
||||
```bash
|
||||
./test.sh openim::test::group
|
||||
```
|
||||
|
||||
### Log Output
|
||||
|
||||
Each test function will output logs to the terminal to confirm the success or failure of the tests. These logs are crucial for identifying issues and verifying that each part of the service is tested thoroughly.
|
||||
|
||||
Each function logs its success upon completion, which aids in debugging and understanding the test flow. The success message is standardized across functions:
|
||||
|
||||
```
|
||||
openim::log::success "<Test suite name> completed successfully."
|
||||
```
|
||||
|
||||
By following the guidelines and instructions outlined in this document, you can effectively utilize the `test.sh` script to test and verify the OpenIM RPC services' functionality.
|
||||
|
||||
|
||||
|
||||
## Function feature
|
||||
|
||||
| Function Name | Corresponding API/Action | Function Purpose |
|
||||
| ---------------------------------------------------- | --------------------------------------------- | ------------------------------------------------------------ |
|
||||
| `openim::test::msg` | Messaging Operations | Tests all aspects of messaging, including sending, receiving, and managing messages. |
|
||||
| `openim::test::auth` | Authentication Operations | Validates the authentication process and session management, including token handling and forced logout. |
|
||||
| `openim::test::user` | User Account Operations | Covers testing for user account creation, retrieval, updating, and overall management. |
|
||||
| `openim::test::friend` | Friend Relationship Operations | Ensures friend management functions correctly, including requests, listing, and blacklisting. |
|
||||
| `openim::test::group` | Group Management Operations | Checks group-related functionalities like creation, invitation, information retrieval, and member management. |
|
||||
| `openim::test::send_msg` | Send Message API | Simulates sending a message from one user to another or within a group. |
|
||||
| `openim::test::revoke_msg` | Revoke Message API (TODO) | (Planned) Will test the revocation of a previously sent message. |
|
||||
| `openim::test::user_register` | User Registration API | Registers a new user in the system to validate the registration process. |
|
||||
| `openim::test::check_account` | Account Check API | Checks if an account exists for a given user ID. |
|
||||
| `openim::test::user_clear_all_msg` | Clear All Messages API | Clears all messages for a given user to validate message history management. |
|
||||
| `openim::test::get_token` | Token Retrieval API | Retrieves an authentication token to validate token management. |
|
||||
| `openim::test::force_logout` | Force Logout API | Forces a logout for a test user to validate session control. |
|
||||
| `openim::test::check_user_account` | User Account Existence Check API | Confirms the existence of a test user's account. |
|
||||
| `openim::test::get_users` | Get Users API | Retrieves a list of users to validate user query functionality. |
|
||||
| `openim::test::get_users_info` | Get User Information API | Obtains detailed information for a given user. |
|
||||
| `openim::test::get_users_online_status` | Get User Online Status API | Checks the online status of a user to validate presence functionality. |
|
||||
| `openim::test::update_user_info` | Update User Information API | Updates a user's information to validate account update capabilities. |
|
||||
| `openim::test::get_subscribe_users_status` | Get Subscribed Users' Status API | Retrieves the status of users that a test user has subscribed to. |
|
||||
| `openim::test::subscribe_users_status` | Subscribe to Users' Status API | Subscribes a test user to a set of user statuses. |
|
||||
| `openim::test::set_global_msg_recv_opt` | Set Global Message Receiving Option API | Sets the message receiving option for a test user. |
|
||||
| `openim::test::is_friend` | Check Friendship Status API | Verifies if two users are friends within the system. |
|
||||
| `openim::test::add_friend` | Send Friend Request API | Sends a friend request from one user to another. |
|
||||
| `openim::test::get_friend_list` | Get Friend List API | Retrieves the friend list of a test user. |
|
||||
| `openim::test::get_friend_apply_list` | Get Friend Application List API | Retrieves friend applications for a test user. |
|
||||
| `openim::test::get_self_friend_apply_list` | Get Self-Friend Application List API | Retrieves the friend applications that the user has applied for. |
|
||||
| `openim::test::add_black` | Add User to Blacklist API | Adds a user to the test user's blacklist to validate blacklist functionality. |
|
||||
| `openim::test::remove_black` | Remove User from Blacklist API | Removes a user from the test user's blacklist. |
|
||||
| `openim::test::get_black_list` | Get Blacklist API | Retrieves the blacklist for a test user. |
|
||||
| `openim::test::create_group` | Group Creation API | Creates a new group with test users to validate group creation. |
|
||||
| `openim::test::invite_user_to_group` | Invite User to Group API | Invites a user to join a group to test invitation functionality. |
|
||||
| `openim::test::transfer_group` | Group Ownership Transfer API | Tests the transfer of group ownership from one member to another. |
|
||||
| `openim::test::get_groups_info` | Get Group Information API | Retrieves information for specified groups to validate group query functionality. |
|
||||
| `openim::test::kick_group` | Kick User from Group API | Simulates kicking a user from a group to test group membership management. |
|
||||
| `openim::test::get_group_members_info` | Get Group Members Information API | Obtains detailed information for members of a specified group. |
|
||||
| `openim::test::get_group_member_list` | Get Group Member List API | Retrieves a list of members for a given group to ensure member listing is functional. |
|
||||
| `openim::test::get_joined_group_list` | Get Joined Group List API | Retrieves a list of groups that a user has joined to validate user's group memberships. |
|
||||
| `openim::test::set_group_member_info` | Set Group Member Information API | Updates the information for a group member to test the update functionality. |
|
||||
| `openim::test::mute_group` | Mute Group API | Tests the ability to mute a group, disabling message notifications for its members. |
|
||||
| `openim::test::cancel_mute_group` | Cancel Mute Group API | Tests the ability to cancel the mute status of a group, re-enabling message notifications. |
|
||||
| `openim::test::dismiss_group` | Dismiss Group API | Tests the ability to dismiss and delete a group from the system. |
|
||||
| `openim::test::cancel_mute_group_member` | Cancel Mute Group Member API | Tests the ability to cancel mute status for a specific group member. |
|
||||
| `openim::test::join_group` | Join Group API (TODO) | (Planned) Will test the functionality for a user to join a specified group. |
|
||||
| `openim::test::set_group_info` | Set Group Information API | Tests the ability to update the group information, such as the name or description. |
|
||||
| `openim::test::quit_group` | Quit Group API | Tests the functionality for a user to leave a specified group. |
|
||||
| `openim::test::get_recv_group_applicationList` | Get Received Group Application List API | Retrieves the list of group applications received by a user to validate application management. |
|
||||
| `openim::test::group_application_response` | Group Application Response API (TODO) | (Planned) Will test the functionality to respond to a group join request. |
|
||||
| `openim::test::get_user_req_group_applicationList` | Get User Requested Group Application List API | Retrieves the list of group applications requested by a user to validate tracking of user's applications. |
|
||||
| `openim::test::mute_group_member` | Mute Group Member API | Tests the ability to mute a specific member within a group, disabling their ability to send messages. |
|
||||
| `openim::test::get_group_users_req_application_list` | Get Group Users Request Application List API | Retrieves a list of user requests for group applications to validate group request management. |
|
||||
8
docs/contrib/util-go.md
Normal file
8
docs/contrib/util-go.md
Normal file
@@ -0,0 +1,8 @@
|
||||
# utils go
|
||||
|
||||
+ [toold readme](https://github.com/openimsdk/open-im-server-deploy/tree/main/tools)
|
||||
|
||||
about scripts fix:
|
||||
```
|
||||
"${OPENIM-ROOT}/_output/bin/tools/${platform}/${lookfor}"
|
||||
```
|
||||
90
docs/contrib/util-makefile.md
Normal file
90
docs/contrib/util-makefile.md
Normal file
@@ -0,0 +1,90 @@
|
||||
# Open-IM-Server Development Tools Guide
|
||||
|
||||
- [Open-IM-Server Development Tools Guide](#open-im-server-deploy-development-tools-guide)
|
||||
- [Introduction](#introduction)
|
||||
- [Getting Started](#getting-started)
|
||||
- [Toolset Categories](#toolset-categories)
|
||||
- [Installation Commands](#installation-commands)
|
||||
- [Basic Installation](#basic-installation)
|
||||
- [Individual Tool Installation](#individual-tool-installation)
|
||||
- [Tool Verification](#tool-verification)
|
||||
- [Detailed Tool Descriptions](#detailed-tool-descriptions)
|
||||
- [Best Practices](#best-practices)
|
||||
- [Conclusion](#conclusion)
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
Open-IM-Server boasts a robust set of tools encapsulated within its Makefile system, designed to ease development, code formatting, and tool management. This guide aims to familiarize developers with the features and usage of the Makefile toolset provided within the Open-IM-Server project.
|
||||
|
||||
## Getting Started
|
||||
|
||||
Executing `make tools` ensures verification and installation of the default tools:
|
||||
|
||||
- golangci-lint
|
||||
- goimports
|
||||
- addlicense
|
||||
- deepcopy-gen
|
||||
- conversion-gen
|
||||
- ginkgo
|
||||
- go-junit-report
|
||||
- go-gitlint
|
||||
|
||||
The installation path is situated at `./_output/tools/`.
|
||||
|
||||
## Toolset Categories
|
||||
|
||||
The Makefile logically groups tools into different categories for better management:
|
||||
|
||||
- **Development Tools**: `BUILD_TOOLS`
|
||||
- **Code Analysis Tools**: `ANALYSIS_TOOLS`
|
||||
- **Code Generation Tools**: `GENERATION_TOOLS`
|
||||
- **Testing Tools**: `TEST_TOOLS`
|
||||
- **Version Control Tools**: `VERSION_CONTROL_TOOLS`
|
||||
- **Utility Tools**: `UTILITY_TOOLS`
|
||||
- **Tencent Cloud Object Storage Tools**: `COS_TOOLS`
|
||||
|
||||
## Installation Commands
|
||||
|
||||
1. **golangci-lint**: high performance Go code linter with integration of multiple inspection tools.
|
||||
2. **goimports**: Used to format Go source files and automatically add or remove imports.
|
||||
3. **addlicense**: Adds a license header to the source file.
|
||||
4. **deepcopy-gen and conversions-gen **: Generate deepcopy and conversion functionality.
|
||||
5. **ginkgo**: Testing framework for Go.
|
||||
6. **go-junit-report**: Converts Go test output to junit xml format.
|
||||
7. **go-gitlint**: For checking git commit information. ... (And so on, list all the tools according to the `make tools.help` output above)...
|
||||
|
||||
|
||||
|
||||
### Basic Installation
|
||||
|
||||
- `tools.install`: Installs tools mentioned in the `BUILD_TOOLS` list.
|
||||
- `tools.install-all`: Installs all tools from the `ALL_TOOLS` list.
|
||||
|
||||
### Individual Tool Installation
|
||||
|
||||
- `tools.install.%`: Installs a single tool in the `$GOBIN/` directory.
|
||||
- `tools.install-all.%`: Parallelly installs an individual tool located in `./tools/*`.
|
||||
|
||||
### Tool Verification
|
||||
|
||||
- `tools.verify.%`: Checks if a specific tool is installed, and if not, installs it.
|
||||
|
||||
## Detailed Tool Descriptions
|
||||
|
||||
The following commands serve the purpose of installing particular development tools:
|
||||
|
||||
- `install.golangci-lint`: Installs `golangci-lint`.
|
||||
- `install.addlicense`: Installs `addlicense`. ... (and so on for every tool as mentioned in the provided Makefile source)...
|
||||
|
||||
The commands primarily leverage Go's `install` operation, fetching and installing tools from their respective repositories. This method is especially convenient as it auto-handles dependencies and installation paths. For tools not written directly with Go (like `install.coscli`), other installation methods like wget or pip are employed.
|
||||
|
||||
## Best Practices
|
||||
|
||||
1. **Regular Updates**: To ensure tools are up-to-date, periodically run the `make tools` command.
|
||||
2. **Individual Tools**: If only specific tools are required, employ the `make install.<tool-name>` command for individual installations.
|
||||
3. **Verification**: Before code submissions, use the `make tools.verify.%` command to guarantee that all necessary tools are present and up-to-date.
|
||||
|
||||
## Conclusion
|
||||
|
||||
The Makefile provided by Open-IM-Server presents a centralized approach to manage and install all necessary tools during the development process. It ensures that all developers employ consistent tool versions, reducing potential issues due to version disparities. Whether you're a maintainer or a contributor to the Open-IM-Server project, understanding the workings of this Makefile will significantly enhance your developmental efficiency.
|
||||
248
docs/contrib/util-scripts.md
Normal file
248
docs/contrib/util-scripts.md
Normal file
@@ -0,0 +1,248 @@
|
||||
# OpenIM Bash Utility Script
|
||||
|
||||
This script offers a variety of utilities and helpers to enhance and simplify operations related to the OpenIM project.
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [OpenIM Bash Utility Script](#openim-bash-utility-script)
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [brief descriptions of each function](#brief-descriptions-of-each-function)
|
||||
- [Introduction](#introduction)
|
||||
- [Usage](#usage)
|
||||
- [SSH Key Setup](#ssh-key-setup)
|
||||
- [openim::util::ensure-gnu-sed](#openimutilensure-gnu-sed)
|
||||
- [openim::util::ensure-gnu-date](#openimutilensure-gnu-date)
|
||||
- [openim::util::check-file-in-alphabetical-order](#openimutilcheck-file-in-alphabetical-order)
|
||||
- [openim::util::require-jq](#openimutilrequire-jq)
|
||||
- [openim::util::md5](#openimutilmd5)
|
||||
- [openim::util::read-array](#openimutilread-array)
|
||||
- [Color Definitions](#color-definitions)
|
||||
- [openim::util::desc and related functions](#openimutildesc-and-related-functions)
|
||||
- [openim::util::onCtrlC](#openimutilonctrlc)
|
||||
- [openim::util::list-to-string](#openimutillist-to-string)
|
||||
- [openim::util::remove-space](#openimutilremove-space)
|
||||
- [openim::util::gencpu](#openimutilgencpu)
|
||||
- [openim::util::gen-os-arch](#openimutilgen-os-arch)
|
||||
- [openim::util::download-file](#openimutildownload-file)
|
||||
- [openim::util::get-public-ip](#openimutilget-public-ip)
|
||||
- [openim::util::extract-tarball](#openimutilextract-tarball)
|
||||
- [openim::util::check-port-open](#openimutilcheck-port-open)
|
||||
- [openim::util::file-lines-count](#openimutilfile-lines-count)
|
||||
|
||||
|
||||
## brief descriptions of each function
|
||||
|
||||
**English:**
|
||||
1. `openim::util::ensure-gnu-sed` - Determines if GNU version of `sed` exists on the system and sets its name.
|
||||
2. `openim::util::ensure-gnu-date` - Determines if GNU version of `date` exists on the system and sets its name.
|
||||
3. `openim::util::check-file-in-alphabetical-order` - Checks if a file is sorted in alphabetical order.
|
||||
4. `openim::util::require-jq` - Checks if `jq` is installed.
|
||||
5. `openim::util::md5` - Outputs the MD5 hash of a file.
|
||||
6. `openim::util::read-array` - Reads content from standard input into an array.
|
||||
7. `openim::util::desc` - Displays descriptive information.
|
||||
8. `openim::util::run::prompt` - Displays a prompt.
|
||||
9. `openim::util::run::maybe-first-prompt` - Possibly displays the first prompt based on whether it's started or not.
|
||||
10. `openim::util::run` - Executes a command and captures its output.
|
||||
11. `openim::util::run::relative` - Returns paths relative to the current script.
|
||||
12. `openim::util::onCtrlC` - Performs an action when Ctrl+C is pressed.
|
||||
13. `openim::util::list-to-string` - Converts a list into a string.
|
||||
14. `openim::util::remove-space` - Removes spaces from a string.
|
||||
15. `openim::util::gencpu` - Retrieves CPU information.
|
||||
16. `openim::util::gen-os-arch` - Generates a repository directory based on the operating system and architecture.
|
||||
17. `openim::util::download-file` - Downloads a file from a URL.
|
||||
18. `openim::util::get-public-ip` - Retrieves the public IP address of the machine.
|
||||
19. `openim::util::extract-tarball` - Extracts a tarball to a specified directory.
|
||||
20. `openim::util::check-port-open` - Checks if a given port is open on the machine.
|
||||
21. `openim::util::file-lines-count` - Counts the number of lines in a file.
|
||||
|
||||
|
||||
|
||||
## Introduction
|
||||
|
||||
This script is mainly used to validate whether the code is correctly formatted by `gofmt`. Apart from that, it offers utilities like setting up SSH keys, various wait conditions, host and platform detection, documentation generation, etc.
|
||||
|
||||
## Usage
|
||||
|
||||
### SSH Key Setup
|
||||
|
||||
To set up an SSH key:
|
||||
|
||||
```bash
|
||||
#1. Write IPs in a file, one IP per line. Let's name it hosts-file.
|
||||
#2. Modify the default username and password in the script.
|
||||
hosts-file-path="path/to/your/hosts/file"
|
||||
openim:util::setup_ssh_key_copy "$hosts-file-path" "root" "123"
|
||||
```
|
||||
|
||||
## openim::util::ensure-gnu-sed
|
||||
|
||||
Ensures the presence of the GNU version of the `sed` command. Different operating systems may have variations of the `sed` command, and this utility function is used to make sure the script uses the GNU version. If it finds the GNU `sed`, it sets the `SED` variable accordingly. If not found, it checks for `gsed`, which is usually the name of GNU `sed` on macOS. If neither is found, an error message is displayed.
|
||||
|
||||
|
||||
|
||||
## openim::util::ensure-gnu-date
|
||||
|
||||
Similar to the function for `sed`, this function ensures the script uses the GNU version of the `date` command. If it identifies the GNU `date`, it sets the `DATE` variable. On macOS, it looks for `gdate` as an alternative. In the absence of both, an error message is recommended.
|
||||
|
||||
|
||||
|
||||
## openim::util::check-file-in-alphabetical-order
|
||||
|
||||
This function checks if the contents of a given file are sorted in alphabetical order. If not, it provides a command suggestion for the user to sort the file correctly.
|
||||
|
||||
|
||||
|
||||
## openim::util::require-jq
|
||||
|
||||
Verifies the installation of `jq`, a popular command-line JSON parser. If it's not present, a prompt to install it is displayed.
|
||||
|
||||
|
||||
|
||||
## openim::util::md5
|
||||
|
||||
A cross-platform function that computes the MD5 hash of its input. This function takes into account the differences in the `md5` command between macOS and Linux.
|
||||
|
||||
|
||||
|
||||
## openim::util::read-array
|
||||
|
||||
A function designed to read from stdin and populate an array, line by line. It's provided as an alternative to `mapfile -t` and is compatible with bash 3.
|
||||
|
||||
|
||||
|
||||
## Color Definitions
|
||||
|
||||
The script also defines a set of colors to enhance its console output. These include colors like red, yellow, green, blue, cyan, etc., which can be used for better user experience and clear logs.
|
||||
|
||||
|
||||
|
||||
## openim::util::desc and related functions
|
||||
|
||||
These functions seem to aid in building interactive demonstrations or tutorials in the terminal. They use the `pv` utility to control the display rate of the output, emulating typing. There's also functionality to handle user prompts and execute commands while capturing their output.
|
||||
|
||||
|
||||
|
||||
## openim::util::onCtrlC
|
||||
|
||||
Handles the `CTRL+C` command. It terminates background processes of the script when the user interrupts it using `CTRL+C`.
|
||||
|
||||
|
||||
|
||||
## openim::util::list-to-string
|
||||
|
||||
Transforms a list format (like `[10023, 2323, 3434]`) to a space-separated string (`10023 2323 3434`). Also removes unnecessary spaces and characters.
|
||||
|
||||
|
||||
|
||||
## openim::util::remove-space
|
||||
|
||||
Removes spaces from a given string.
|
||||
|
||||
|
||||
|
||||
## openim::util::gencpu
|
||||
|
||||
Fetches the number of CPUs using the `lscpu` command.
|
||||
|
||||
|
||||
|
||||
## openim::util::gen-os-arch
|
||||
|
||||
Identifies the operating system and architecture of the system running the script. This is useful to determine directories or binaries specific to that OS and architecture.
|
||||
|
||||
|
||||
|
||||
## openim::util::download-file
|
||||
|
||||
This function can be used to download a file from a URL. If `curl` is available, it uses `curl`. If not, it falls back to `wget`.
|
||||
|
||||
```bash
|
||||
function openim::util::download-file() {
|
||||
local url="$1"
|
||||
local dest="$2"
|
||||
|
||||
if command -v curl &>/dev/null; then
|
||||
curl -L "${url}" -o "${dest}"
|
||||
elif command -v wget &>/dev/null; then
|
||||
wget "${url}" -O "${dest}"
|
||||
else
|
||||
openim::log::error "Neither curl nor wget available. Cannot download file."
|
||||
return 1
|
||||
fi
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## openim::util::get-public-ip
|
||||
|
||||
Fetches the public IP address of the machine.
|
||||
|
||||
```bash
|
||||
function openim::util::get-public-ip() {
|
||||
if command -v curl &>/dev/null; then
|
||||
curl -s https://ipinfo.io/ip
|
||||
elif command -v wget &>/dev/null; then
|
||||
wget -qO- https://ipinfo.io/ip
|
||||
else
|
||||
openim::log::error "Neither curl nor wget available. Cannot fetch public IP."
|
||||
return 1
|
||||
fi
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## openim::util::extract-tarball
|
||||
|
||||
This function extracts a tarball to a specified directory.
|
||||
|
||||
```bash
|
||||
function openim::util::extract-tarball() {
|
||||
local tarball="$1"
|
||||
local dest="$2"
|
||||
|
||||
mkdir -p "${dest}"
|
||||
tar -xzf "${tarball}" -C "${dest}"
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## openim::util::check-port-open
|
||||
|
||||
Checks if a given port is open on the local machine.
|
||||
|
||||
```bash
|
||||
function openim::util::check-port-open() {
|
||||
local port="$1"
|
||||
if command -v nc &>/dev/null; then
|
||||
echo -n > /dev/tcp/127.0.0.1/"${port}" 2>&1
|
||||
return $?
|
||||
elif command -v telnet &>/dev/null; then
|
||||
telnet 127.0.0.1 "${port}" 2>&1 | grep -q "Connected"
|
||||
return $?
|
||||
else
|
||||
openim::log::error "Neither nc nor telnet available. Cannot check port."
|
||||
return 1
|
||||
fi
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## openim::util::file-lines-count
|
||||
|
||||
Counts the number of lines in a file.
|
||||
|
||||
```bash
|
||||
function openim::util::file-lines-count() {
|
||||
local file="$1"
|
||||
if [[ -f "${file}" ]]; then
|
||||
wc -l < "${file}"
|
||||
else
|
||||
openim::log::error "File does not exist: ${file}"
|
||||
return 1
|
||||
fi
|
||||
}
|
||||
```
|
||||
238
docs/contrib/version.md
Normal file
238
docs/contrib/version.md
Normal file
@@ -0,0 +1,238 @@
|
||||
# OpenIM Branch Management and Versioning: A Blueprint for High-Grade Software Development
|
||||
|
||||
[📚 **OpenIM TOC**](#openim-branch-management-and-versioning-a-blueprint-for-high-grade-software-development)
|
||||
- [OpenIM Branch Management and Versioning: A Blueprint for High-Grade Software Development](#openim-branch-management-and-versioning-a-blueprint-for-high-grade-software-development)
|
||||
- [Unfolding the Mechanism of OpenIM Version Maintenance](#unfolding-the-mechanism-of-openim-version-maintenance)
|
||||
- [Main Branch: The Heart of OpenIM Development](#main-branch-the-heart-of-openim-development)
|
||||
- [Release Branch: The Beacon of Stability](#release-branch-the-beacon-of-stability)
|
||||
- [Tag Management: The Cornerstone of Version Control](#tag-management-the-cornerstone-of-version-control)
|
||||
- [Release Management: A Guided Tour](#release-management-a-guided-tour)
|
||||
- [Milestones, Branching, and Addressing Major Bugs](#milestones-branching-and-addressing-major-bugs)
|
||||
- [Version Skew Policy](#version-skew-policy)
|
||||
- [Supported version skew](#supported-version-skew)
|
||||
- [OpenIM Versioning, Branching, and Tag Strategy](#openim-versioning-branching-and-tag-strategy)
|
||||
- [Supported Version Skew](#supported-version-skew-1)
|
||||
- [openim-api](#openim-api)
|
||||
- [openim-rpc-\* Components](#openim-rpc--components)
|
||||
- [Other OpenIM Services](#other-openim-services)
|
||||
- [Supported Component Upgrade Order](#supported-component-upgrade-order)
|
||||
- [openim-api](#openim-api-1)
|
||||
- [openim-rpc-\* Components](#openim-rpc--components-1)
|
||||
- [Other OpenIM Services](#other-openim-services-1)
|
||||
- [Conclusion](#conclusion)
|
||||
- [Applying Principles: A Git Workflow Example](#applying-principles-a-git-workflow-example)
|
||||
- [Release Process](#release-process)
|
||||
- [Docker Images Version Management](#docker-images-version-management)
|
||||
- [More](#more)
|
||||
|
||||
|
||||
At OpenIM, we acknowledge the profound impact of implementing a robust and efficient version management system, hence we abide by the established standards of [Semantic Versioning 2.0.0](https://semver.org/lang/zh-CN/).
|
||||
|
||||
Our software blueprint orchestrates a tripartite version management system that integrates the `main` branch, the `release` branch, and `tag` management. These constituents operate in synchrony to preserve the reliability and traceability of our software across various stages of development.
|
||||
|
||||
## Unfolding the Mechanism of OpenIM Version Maintenance
|
||||
|
||||
Our version maintenance protocol revolves around two primary branches, namely: `main` and `release`. We resort to Semantic Versioning 2.0.0 for marking distinctive versions of our software, representing substantial milestones in its evolution.
|
||||
|
||||
In the OpenIM repository, version identification strictly complies with the `MAJOR.MINOR.PATCH` protocol. Herein:
|
||||
|
||||
- The `MAJOR` version indicates a shift arising from incompatible changes to the API.
|
||||
- The `MINOR` version suggests the addition of features in a backward-compatible manner.
|
||||
- The `PATCH` version flags backward-compatible bug fixes.
|
||||
|
||||
## Main Branch: The Heart of OpenIM Development
|
||||
|
||||
The `main` branch is the operational heart of our development process. Housing the most recent and advanced features, this branch serves as the nerve center for all enhancements and updates. It encapsulates the freshest, though possibly unstable, facets of the software. Visit our `main` branch [here](https://github.com/openimsdk/open-im-server-deploy/tree/main).
|
||||
|
||||
## Release Branch: The Beacon of Stability
|
||||
|
||||
For every major release, we curate a corresponding `release` branch, e.g., `release-v3.1`. This branch symbolizes an embodiment of stability and ensures an updated version of the software, providing a dependable option for users favoring stability over nascent, yet possibly unstable, features. Visit the `release-v3.1` branch [here](https://github.com/openimsdk/open-im-server-deploy/tree/release-v3.1).
|
||||
|
||||
## Tag Management: The Cornerstone of Version Control
|
||||
|
||||
In OpenIM's version control system, the role of `tags` stands paramount. Owing to their immutable nature, tags can be effectively utilized to retrieve a specific version of the software. Explore our library of tags [here](https://github.com/openimsdk/open-im-server-deploy/tags).
|
||||
|
||||
Our Docker image versions are intimately entwined with these tripartite components. For instance, a Docker image tag may correspond to `ghcr.io/openimsdk/openim-server:v3.1.0`, a release to `ghcr.io/openimsdk/openim-server:release-v3.0`, and the main branch to `ghcr.io/openimsdk/openim-server:main` or `ghcr.io/openimsdk/openim-server:latest`.
|
||||
|
||||
To further clarify, the semantics of our version numbers are as follows:
|
||||
|
||||
- **Revision version number**: This represents bug fixes or code optimizations. Typically, it entails no new feature additions and ensures backward compatibility.
|
||||
- **Build version number**: Auto-generated by the system, each code submission prompts an automatic increment by 1.
|
||||
- **Version modifiers**: These hint at the software's development stage and stability. Some commonly used modifiers are `alpha`, `beta`, `rc`, `ga`, `r/release/or nothing`, and `lts`.
|
||||
- `alpha`: An internal testing version with numerous bugs, typically used for communication among developers.
|
||||
- `beta`: A test version with numerous bugs, generally used for testing by eager community members, who provide feedback to the developers.
|
||||
- `rc`: Release candidate, which is to be released as the official version. It's the last test version before the official version.
|
||||
- `ga`: General Availability, the first stable release.
|
||||
- `r/release/or nothing`: The final release version, intended for general users.
|
||||
- `lts`: Long Term Support, the official will specify the maintenance year for this version and will fix all bugs discovered in this version.
|
||||
|
||||
Whenever a project undergoes a partial functional addition, the minor version number increments by 1, resetting the revision version number to 0. In contrast, any major project overhaul results in an increment by 1 in the major version number. The build number, typically auto-generated during the compilation process, only requires format definition, thereby eliminating manual control.
|
||||
|
||||
## Release Management: A Guided Tour
|
||||
|
||||
Our GitHub repository at https://github.com/openimsdk/open-im-server-deploy/releases associates a release with each tag, with a distinction between Pre-release and Latest, determined by the branch source. Every significant feature launch prompts the issue of a `release` branch, such as `release-v3.2`, as a beacon of stability and Latest release.
|
||||
|
||||
Pre-releases correspond to releases from the `main` branch, denoting tags with Version modifiers such as `v3.2.1-beta.0`, `v3.2.1-rc.1`, etc. If you are seeking the most recent, albeit possibly unstable, release with new features, these tags, originating from the latest `main` branch code, are your go-to.
|
||||
|
||||
Conversely, if stability is your primary concern, you should opt for the release tagged Latest, denoted by tags without Version modifiers, such as `v3.2.1`, `v3.2.2` etc. These tags are linked to the latest stable maintenance branch, like `release-v3.2`.
|
||||
|
||||
## Milestones, Branching, and Addressing Major Bugs
|
||||
|
||||
**About:**
|
||||
|
||||
+ [OpenIM Milestones](https://github.com/openimsdk/open-im-server-deploy/milestones)
|
||||
+ [OpenIM Tags](https://github.com/openimsdk/open-im-server-deploy/tags)
|
||||
+ [OpenIM Branches](https://github.com/openimsdk/open-im-server-deploy/branches)
|
||||
|
||||
We create a new branch, such as `release-v3.1`, for each significant milestone (e.g., v3.1.0), housing all relevant code for that release. All enhancements and bug fixes targeting the subsequent version (e.g., v3.2.0) are integrated into this branch.
|
||||
|
||||
`PATCH` versions (represented by Z in `X.Y.Z`) are primarily propelled by bug fixes, and their release may be either priority-driven or scheduled. In contrast, `MINOR` versions (represented by Y in `X.Y.Z`) are contingent upon the project's roadmap, milestone completion, or a pre-established timeline, always maintaining backward-compatible APIs.
|
||||
|
||||
When dealing with major bugs, we selectively merge the fix into the affected version (e.g., v3.1 or the `release-v3.1` branch), as well as the `main` branch. This dual pronged strategy ensures that users on older versions receive crucial bug fixes, while also keeping the `main` branch updated.
|
||||
|
||||
We reinforce our approach to branch management and versioning with stringent testing protocols. Automated tests and code review sessions form vital components of maintaining a robust and reliable codebase.
|
||||
|
||||
## Version Skew Policy
|
||||
|
||||
This document describes the maximum version skew supported between various openim components. Specific cluster deployment tools may place additional restrictions on version skew.
|
||||
|
||||
### Supported version skew
|
||||
|
||||
In highly-available (HA) clusters, the newest and oldest `openim-api` instances must be within one minor version.
|
||||
|
||||
### OpenIM Versioning, Branching, and Tag Strategy
|
||||
|
||||
Similar to Kubernetes, OpenIM has a strict versioning, branching, and tag strategy to ensure compatibility among its various services and components. This document outlines the policies, especially focusing on the version skew supported between OpenIM's components. Given that the current version is v3.3, the policy references will be centered around this version.
|
||||
|
||||
#### Supported Version Skew
|
||||
|
||||
##### openim-api
|
||||
|
||||
In highly-available (HA) clusters, the newest and oldest `openim-api` instances must be within one minor version.
|
||||
|
||||
Example:
|
||||
|
||||
+ Newest `openim-api` is at v3.3
|
||||
+ Other `openim-api` instances are supported at v3.3 and v3.2
|
||||
|
||||
##### openim-rpc-* Components
|
||||
|
||||
All `openim-rpc-*` components (e.g., `openim-rpc-auth`, `openim-rpc-conversation`, etc.) should adhere to the following rules:
|
||||
|
||||
1. They must not be newer than `openim-api`.
|
||||
2. They may be up to one minor version older than `openim-api`.
|
||||
|
||||
Example:
|
||||
|
||||
+ `openim-api` is at v3.3
|
||||
+ All `openim-rpc-*` components are supported at v3.3 and v3.2
|
||||
|
||||
Note: If version skew exists between `openim-api` instances in an HA cluster, this narrows the allowed `openim-rpc-*` components versions.
|
||||
|
||||
##### Other OpenIM Services
|
||||
|
||||
Other OpenIM services such as `openim-cmdutils`, `openim-crontask`, `openim-msggateway`, etc. should adhere to the following rules:
|
||||
|
||||
1. These services must not be newer than `openim-api`.
|
||||
2. They are expected to match the `openim-api` minor version but may be up to one minor version older (to allow live upgrades).
|
||||
|
||||
Example:
|
||||
|
||||
+ `openim-api` is at v3.3
|
||||
+ `openim-msggateway`, `openim-cmdutils`, and other services are supported at v3.3 and v3.2
|
||||
|
||||
#### Supported Component Upgrade Order
|
||||
|
||||
The version skew policy has implications on the order in which components should be upgraded. Below is the recommended order to transition an existing cluster from version v3.2 to v3.3:
|
||||
|
||||
##### openim-api
|
||||
|
||||
Pre-requisites:
|
||||
|
||||
1. In a single-instance cluster, the existing `openim-api` instance is v3.2.
|
||||
2. In an HA cluster, all `openim-api` instances are at v3.2 or v3.3.
|
||||
3. All `openim-rpc-*` and other OpenIM services communicating with this server are at version v3.2.
|
||||
|
||||
Upgrade Procedure:
|
||||
|
||||
1. Upgrade `openim-api` to v3.3.
|
||||
|
||||
##### openim-rpc-* Components
|
||||
|
||||
Pre-requisites:
|
||||
|
||||
1. The `openim-api` instances these components communicate with are at v3.3.
|
||||
|
||||
Upgrade Procedure:
|
||||
|
||||
2. Upgrade all `openim-rpc-*` components to v3.3.
|
||||
|
||||
##### Other OpenIM Services
|
||||
|
||||
Pre-requisites:
|
||||
|
||||
1. The `openim-api` instances these services communicate with are at v3.3.
|
||||
|
||||
Upgrade Procedure:
|
||||
|
||||
2. Upgrade other OpenIM services such as `openim-msggateway`, `openim-cmdutils`, etc., to v3.3.
|
||||
|
||||
#### Conclusion
|
||||
|
||||
Just like Kubernetes, it's essential for OpenIM to have a strict versioning and upgrade policy to ensure seamless operation and compatibility among its various services. Adhering to the policies outlined above will help in achieving this goal.
|
||||
|
||||
|
||||
## Applying Principles: A Git Workflow Example
|
||||
|
||||
The workflow to address a bug fix might follow these steps:
|
||||
|
||||
```bash
|
||||
# Checkout the branch for the version that needs the bug fix
|
||||
git checkout release-v3.1
|
||||
|
||||
# Create a new branch for the bug fix
|
||||
git checkout -b bug/bug-name
|
||||
|
||||
# ... Make changes, commit your work ...
|
||||
|
||||
# Push the branch to your remote repository
|
||||
git push origin bug/bug-name
|
||||
|
||||
# After the pull request is merged into the release-v3.1 branch,
|
||||
# checkout and update your main branch
|
||||
git checkout main
|
||||
git pull origin main
|
||||
|
||||
# Merge or rebase the changes from release-v3.1 into main
|
||||
git merge release-v3.1
|
||||
|
||||
# Push the updates to the main branch
|
||||
git push origin main
|
||||
```
|
||||
|
||||
## Release Process
|
||||
|
||||
```
|
||||
Publishing v3.2.0: A Step-by-Step Guide
|
||||
(1) Create the tag v3.2.0-alpha.0 from the main branch.
|
||||
(2) Bugs are fixed on the main branch. Once the bugs are resolved, tag the main branch as v3.2.0-rc.0.
|
||||
(3) After further testing, if v3.2.0-rc.0 is deemed stable, create a branch named release-v3.2 from the tag v3.2.0-rc.0.
|
||||
(4) From the release-v3.2 branch, create the tag v3.2.0. At this point, the official release of v3.2.0 is complete.
|
||||
|
||||
After the release of v3.2.0, if urgent bugs are discovered, fix them on the release-v3.2 branch. Then, submit two pull requests (PRs) to both the main and release-v3.2 branches. Tag the release-v3.2 branch as v3.2.1.
|
||||
```
|
||||
|
||||
Throughout this process, active communication within the team is pivotal to maintaining transparency and consensus on changes.
|
||||
|
||||
## Docker Images Version Management
|
||||
|
||||
For more details on managing Docker image versions, visit [OpenIM Docker Images Administration](https://github.com/openimsdk/open-im-server-deploy/blob/main/docs/contrib/images.md).
|
||||
|
||||
## More
|
||||
|
||||
More on multi-branch version management design and version management design at helm charts:
|
||||
|
||||
About Helm's version management strategy for Multiple Apps and multiple Services:
|
||||
|
||||
+ [中文版本管理文档](https://github.com/openimsdk/helm-charts/blob/main/docs/contrib/version-zh.md)
|
||||
+ [English version management documents](https://github.com/openimsdk/helm-charts/blob/main/docs/contrib/version.md)
|
||||
Reference in New Issue
Block a user